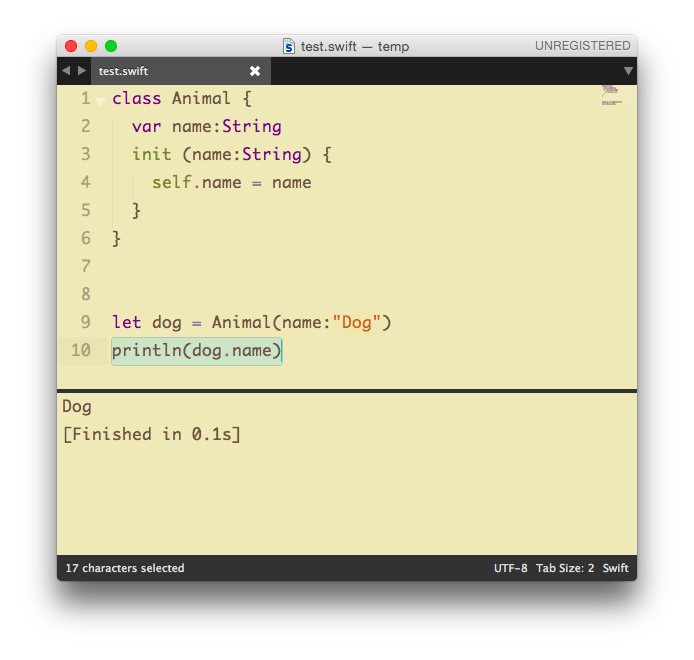
OSXDev에서 열린 Coding Dojo에 다녀왔다. 보통 Dojo가 붙은 사이트들을 생각해서 이해하지 못하면 어쩌나 긴장했는데 다행히 난이도는 예상보다 낮았다. 타겟은 "책을 읽었다"와 "이해했다" 사이의 사람이 대상인 것 같다. 그러니까 책은 읽었는데 어떻게 써야할지 감이 안오는 사람들을 위한 '체득'의 시간 정도? 문제를 풀어보고 해석하고의 반복으로 진행되어 네 문제를 풀었다.
팁, 경우에 따라 다르겠지만 Boolean만 처리하지 말고 Optional에서 nil일 때도 처리해주는게 좋다.
2. switch에서의 pattern matching
복잡한 케이스에 대해서 switch-case를 단순히 objective-c에서 사용했던 것처럼 쓰거나 if-else문을 반복하는 것보다 tuple로 묶어서 한번에 처리하면 깔끔하고, where절(guard)을 통해 조건을 처리하면 더 깔끔하게 처리된다.
팁, pattern matching에서는 분기가 길어지면 case가 switch문과 거리가 멀어져서 어떤 의미인지 알기 어려운데, 특히 case에 true/false를 사용하는 경우 의미를 바로 알기 어려우므로 enum을 사용해서 의미있는 값을 변수로 만들어서 표현하면 좋다.
3. 간단한 알고리즘 풀이
중첩된 for문을 어떻게 사용하는지에 대한 문제. 참고로 100 doors 문제였다.
4. repeatString
String에 대한 기본 사용법(concat)과 loop 등을 사용한 정해진 횟수의 문자열 반복.
진도가 Control Flow까지만여서 그 안에서만으로 해결할 수 있는 문제들을 짧은 시간 내에 제출하느라 고생하셨으리라 생각된다.
덧 1, 4번 문제의 경우 제약 때문에 함수로 구현했지만 operator overloading을 통해 쓰기 좋게 만들 수도 있다.
덧 2, swift 프로젝트에서 다른 파일에 구현을 해도 하나로 묶어서 해석하므로 같은 이름의 함수를 구현하면 에러가 난다는 질문이 있었는데, 얼마 전에 추가된 접근자(access control)을 통해 해결할 수 있을 줄 알고 시도해봤지만 안된다. c처럼 static 키워드가 생기거나 다른 방법을 찾아봐야겠다.
Translation of "Optimization killers" into Korean, under the same license as the original.
도입
이 문서는 예상보다 훨씬 성능이 떨어지는 코딩을 피하기 위한 조언이 포함되어 있다. 특히 V8(nodejs, Opera, Chromium 등)에서 최적화를 방해하는 패턴에 대한 것이다.
V8 배경지식 약간
V8에서는 인터프리터가 없고 2가지 컴파일러가 있다, 일반 컴파일러(generic)와 최적화 컴파일러(optimizing).
즉, JavaScript 코드를 항상 컴파일하고 네이티브로 직접 실행한다는 뜻이다. 이는 빠르다는 뜻이다, 정말? 아니다. 네이티브로 컴파일된 코드라고 해서 성능적으로 큰 의미가 있는 것은 아니다. 단지 인터프리터 과부하를 제거한 것이라 최적화되지 않은 코드는 여전히 느리게 돌아간다.
예를 들어, 일반 컴파일러로 a + b는 다음과 같다.
1 2 3
mov eax, a mov ebx, b call RuntimeAdd
위에서 보면 단지 런타임 함수를 호출한다. a와 b가 항상 정수라면 다음과 같이 된다.
1 2 3
mov eax, a mov ebx, b add eax, ebx
런타임에서 복잡한 의미가 추가된 스크립트보다 훨씬 빠르게 작동할 것이다.
전자는 일 컴파일러에서 나오는 코드고, 후자는 최적화 컴파일러에서 나오는 코드다. 최적화 컴파일러로 컴파일된 코드는 대충 일반 컴파일러로 생성한 것보다 100배쯤 빠르다. 여기서 잠깐, 그냥 JavaScript로 코딩한다고 최적화된다는 것은 아니다. 많은 패턴들이 있는데, 최적화 컴파일러가 건들지 못하는 관용적인 것들이 있다.
중요한 점은, 이렇게 최적화 제외 코드는 그 함수를 포함하는 전체에 영향을 준다는 것이다. 코드는 한번에 한 함수만 최적화가 되고, 다른 코드가 무엇을 하든 전혀 모르고 있다(현재 최적화하고 있는 함수 내에 인라인된 코드가 아니라면).
이 가이드는 "비최적화"의 함수를 포함해 대부분의 패턴을 다룬다. 최적화 컴파일러가 더 많은 패턴을 인식할 수 있도록 업데이트 될 때 이런 우회 방법들은 불필요해질 것이다.
var result = tryCatch(mightThrow, void0, [1,2,3]); //Unambiguously tells whether the call threw if(result === errorObject) { var error = errorObject.value; } else { //result is the returned value }
3. arguments 관리
3.1. arguments를 함수 내에서 사용하면서 파라미터로 넘겨준 변수에 다른 값을 넣을 때
1 2 3
functiondefaultArgsReassign(a, b) { if (arguments.length < 2) b = 5; }
우회
1 2 3 4 5
functionreAssignParam(a, b_) { var b = b_; //unlike b_, b can safely be reassigned if (arguments.length < 2) b = 5; }
혹은
1 2 3
functionreAssignParam(a, b) { if (b === void0) b = 5; }
3.2. arguments를 외부로 노출
1 2 3 4 5 6 7 8 9 10 11 12
functionleaksArguments1() { returnarguments; } functionleaksArguments2() { var args = [].slice.call(arguments); } functionleaksArguments3() { var a = arguments; returnfunction() { return a; }; }
우회
1 2 3 4 5 6 7
functiondoesntLeakArguments() { var args = newArray(arguments.length); for(var i = 0; i < args.length; ++i) { args[i] = arguments[i]; } return args; }
설명: vcprompt를 이용해서 bash 프롬프트에 VCS 정보 표시하기
기본 구조: (<형상관리 이름>:<브랜치 이름> )
비고: VCS 이름, commit hash, branch, revision, modified file, not-added 등 각종 변수 지원
Bash prompot에서 Git 정보 보기
GitHub: magicmonty/bash-git-prompt
기본 구조: (<브랜치 이름> <브랜치 상태>|<로컬 상태>)
설명: 리눅스 bash shell에서 git 상태 정보 보기
비고: add, conflict, modified, non-added, stashed, yet-pushed, yet-pulled 상태의 숫자 등 표시
결론
vcprompt를 이용했다. 이유는 homebrew로 설치 가능한 유일한 방법이라 설치하기가 쉬워서. 이전의 설정은 다음과 같다.
coursera.org의 functional programming principle in scala의 진행이 끝났다. functional programming이라는 생소한 개념을 배우면서 재미있기도 했고, 강의를 시작하기 직전에 봤던 '자바 개발자를 위한 함수형 프로그래밍'를 읽으면서 제대로 알지 못했던 개념을 좀 더 확실하게 배웠다. 물론 강의와 서적 모두 '입문'에 대한 것이라 의미에 대해 알려면 더 많은 경험이 필요하겠고, 서적과 강의가 지향하는 바가 조금 달라서 내용도 다르지만 서적을 보면서 제대로 이해하지 못했던 개념을 강의를 보면서 이해하는데 도움이 되었고 기초가 있는 상태에서 다시 서적을 읽으면 더 이해가 잘 될 것 같다.
사실 강의를 읽으면서 도움이 된 것은 functional programming에 대한 이해보다 다른 것이다. 물론 functional programming에 대한 기초를 쌓는데도 무척 도움이 되었지만, 그것보다 과제를 진행하는데 있어서 '테스트'의 중요성에 대한 인식이 생겼다.
과제를 진행하는 방식은 이렇다.
테스트 케이스가 주어진다.
작성해야하는 로직이 제외된 코드가 주어진다.
단계별로 로직을 구현하면서 테스트를 통해 작성된 로직이 유효한지 확인한다.
이전 단계에서 구현한 것을 기반으로 다음 단계의 로직을 작성한다.
물론 주어진 테스트 케이스들 중에서 좋은 테스트 케이스만 있는 것이 아니다. 스펙에서 요구되었지만 테스트에서 확인하지 않은 케이스(정렬된 배열을 가져와야하는데 그 종류와 갯수만 확인하는 경우)는 다음 단계의 테스트를 통과하지 못한다. 그럴 경우에는 테스트에 성공한 코드로 돌아가서 수정을 해야하므로 좋은 테스트라고 볼 수 없다. 이런 식으로 좋은 테스트가 적성되어있는 경우에는 그 테스트를 통과하면 다시 그 코드를 수정할 필요가 없고, 성능상의 문제가 있는 경우에는 그 코드를 수정하고 다시 테스트를 통과하면 다른 코드들을 건들이지 않아도 된다.
여기에 대한 전제가 중요하긴 하다. 앞서 이야기했듯이 '좋은(명확한) 테스트가 작성되어 있을 것', 그리고 '확실히 단계별로 구분된 설계가 있을 것'이다. 이 전제들이 참 어렵지만, 반대로 생각하면 이 전제들이 확실한 경우가 있다. 바로 내가 겪었던 것과 같이 '과제'를 작성하는 경우다. 커다란 과제가 주어졌을 경우에 어디서부터 어떻게 접근해야할지 명세서를 봐도 막막한 경우가 있는데 그런 경우에 bottom-up으로 제대로 된 설계에 따라 테스트를 하나씩 거치면서 확실히 눈에 보이는 진척을 확인할 수 있다. 물론 실무에 적용하려면 저 전제들을 만족하기 참 힘들겠지만 말이다. 혹은 퍼포먼스의 이슈가 없거나 종속성이 적은 코드들의 경우에 신입사원들에게 연습시키는 용도로는 확실할 수 있다.
예전에 일하던 회사에서 '시켜서' 억지로 작성한 테스트들이 떠오르며 (사실 잘 떠오르지도 않지만) 부끄러워졌다. 사실 TDD라고 하지만 아직도 TDD가 뭔지 잘 모르겠고, 이해하지 못한 상태에서 작성한 테스트들은 당연히 좋은 테스트일리가 없었다. 이렇게 실무에서 어떻게 테스트를 더 잘 적용시킬 수 있는지에 대해 듣고 싶어서 저번달에 모 컨퍼런스에 다녀왔는데 그냥 '테스트는 의지를 가지고 해야 한다.'라는 말만 반복해서 하더라. 하긴 누군가가 말해줘도 그걸 체득하기는 어렵다. 계기와 경험이 중요한데 나는 일단 이 강의라는 계기를 얻었으니 앞으로 경험을 쌓도록 노력해야지.
참고로 80점 만점에서 60%(48점)만 얻으면 인증을 얻는데 과제를 너무 늦게 시작하는 바람에 1주차에 80% 감점을 받고 시작한 것을 합쳐서 69점으로 통과했다. 만점을 목표로 한 것에 비하면 부끄럽지만 인증을 받은 것만으로도 일단은 만족. 그리고 스칼라 스터디에 한번 참여해보고 싶었는데 영어 실력이 부족하여 참여할만큼 이해한 강의가 없어서 한번도 참여를 못한 것 두가지가 아쉽다.
들어가기 전에, functional javascript 자바스크립트의 함수형 프로그래밍에 대한 간략한 소개가 있는 슬라이드. 함수형 프로그래밍에 개념과 underscore의 컨셉을 이해하는데 도움이 된다.
Underscore.js와 만나다
그래서 Underscore가 정확히 뭐하는건데?
Underscore는 Prototype.js(혹은 Ruby)처럼 기본 JavaScript 객체들을 확장하지 않고 함수형 프로그래밍을 지원할 수 있는 유용한 JavaScript Library이다.
Python이나 Ruby로 작업할 때 더 좋은 점은 훨씬 쉽게 쓸 수 있는 map같은 멋진 기본함수들이 있다는 것이다. 슬프게도 JavaScript의 현재 버전에서는 그런 native로 제공되는 것들이 꽤나 부실하다. 위에서 읽은 것처럼, Underscore.js는 단지 4kb라는 터무니없는 용량의 좀 멋진 JavaScript Library다.
Underscore in Action
"라이브러리 이야기는 충분히 많이 들었다", 라는 말할지도 모른다. 맞다, 하지만 일단 한번 보자. 임의의 시험점수 배열에서 90점 넘는 리스트가 필요하면 보통은 이렇게 짤 것이다.
모든건 뭘 하려고 하는지에 달렸다. 단지 DOM 다루는데 사용을 제한한다면 jQuery로 원하는건 대부분 할 수 있다. 반대로, DOM이랑 관련없거나 좀 복잡한 MVC나 front-end 코드들이라면 underscore는 확실히 괜찮다. ECMA 스펙에 맞춰서 천천히 라이브러리들의 기능이 업데이트되는 동안에, 모든 브라우져에서 돌아가는건 가능하지도 않고 여러 브라우저들에서 돌아가게 하는 것도 또다른 악몽이다. underscore는 어디서든 작동하도록 좋은 추상화를 제공한다. 그리고 퍼포먼스를 중시하는 사람이거나 그래야하는 사람이면 underscore는 가능한 native 뒤에 구현된거라 가능한 최적화된 성능을 보장한다.
적용시키는데 뭔가 큰 작업을 기대했으면 꽤나 실망할꺼다. 그냥 여기에서 소스를 가져다 넣기만 하면 페이지는 잘 돌아간다. underscore는 global 영역에서 단일 객체로 만들어지고 모든 기능을 한다. 이 객체는 underscore 문자, _로 불린다. 흥미롭게도 jQuery가 dollar 문자($)로 돌아가는 것과 매우 비슷해 보인다. 또 jQuery처럼 충돌을 피하려면 다른 문자로 쓸 수도 있다.
함수형? 아니면 객체지향?
라이브러리의 공식적인 광고에는 함수형 프로그래밍 지원이라고 써있는데, 실제로 쓰는 다른 방법도 있다. 저 위에서 썼던 예제를 가져와보면
실제로 '정답'이라는건 없지만, jQuery식으로 method 뒤에 chainging을 할 수 있다는 것을 알아두라.
기능을 확인해보자
underscore는 기능 자체의 숫자보다 많은 60개보다 조금 넘는 함수를 지원한다. 돌아가는 함수들을 그룹으로 다음과 같이 분류할 수 있다.
Collections
Arrays
Objects
Functions
Utilities
각각 뭘 하는지를 보고, 가능하면 섹션에서 한두개쯤 적용해보겠다.
Collections
connection은 배열이나 객체가 될 수 있고, 의미상으로 말하자면 자바스크립트에서의 (객체와 배열이)혼합된 배열이다. underscore는 collections에서 돌아가는 많은 method들을 제공한다. 위에서 이미 select를 봤다. 여기 더 쓸만한게 하나 있다.
Pluck
key와 value 쌍으로 이루어진 깔끔하고 짧은 배열이 있는데 여기에서 특정 속성을 추출하려고 한다. underscore로는 아주 쉽다.
좀 이상하게 들리지만, underscore는 함수에서 돌아가는 함수들을 갖고 있다. 함수들의 대부분은 설명하기 복잡한 것들이어서 제일 간단한 것을 가져왔다.
Bind
this는 JavaScript에서 설명하기 힘든 부분이고 많은 개발자들을 멘붕하게 만든다. 이 method는 그나마 건들기 쉽게 해준다.
1 2 3 4 5 6
var o = { greeting: "Howdy" }, f = function(name) { returnthis.greeting +" "+ name; };
var greet = _.bind(f, o);
greet("Jess")
헷갈려서 계속 쳐다보게 만든다. bind 함수는 기본적으로 함수가 어디에서 언제 호출이되건 this값을 유지하게 해준다. this를 가져다가 event를 다룰 때 특별히 유용하다.
Utilities
그리고 쓰기에 더 괜찮은게, underscore는 utility 함수들을 대량으로 지원한다. 시간이 없으니 크고 아름다운 것 하나만 보자.
Templating
이미 template을 만드는 많은 solution들이 있지만 underscore는 강력하면서 구현이 적다는데 장점이 있다. 대충 예제를 하나 만들어보면
1 2 3 4 5 6 7
var data = {site: 'NetTuts'}, template = 'Welcome! You are at <%= site %>';
var parsedTemplate = _.template(template, data );
console.log(parsedTemplate);
// Welcome! You are at NetTuts
우선, template를 통해 template으로 옮겨서 데이터를 만들 수 있다. 기본적으로, underscore는 모두 custom할 수 있는 ERB(embeded Ruby) 스타일 문자를 사용한다. 그 자리에, template과 data를 가지고 template을 간단하게 호출하면 된다. 필요하면 나중에 업데이트하기 위해 분리된 문자열에 결과를 저장한다.
이건 underscore의 template 중에서 극단적으로 간단한 예제라는걸 명심해라. <% %> 문자를 이용한 template 안쪽에서 어떤 JavaScript 코드를 사용할 수 있다. JSON같은 복잡한 객체를 훑을 필요가 있을 때에는 underscore의 우수한 collection 함수들과 함께 template을 빠르게 만들 수도 있다.
여전히 왜 써야하는지 모르겠다면
jQuery와 underscore를 함께
jQuery와 underscore는 상호보완적인 것이라 함께 쓰면 더 좋다. 자, jQuery는 아주 괜찮은 케이스들도 있다. DOM을 다룬다거나 애니메이션같은 것들이 말이다. 하지만 더 고수준이나 저수준을 다루지는 않는다. 고수준 이슈를 다루는 Backbone이나 Knockout같은 프레임웍이라면 필요한 부분에 전부 끼워넣을 수 있다.
좀 더 넓게 보자면, jQuery는 DOM을 다루는 기능 때문에 브라우저 밖에서는 거의 쓸 일이 없다. 다른 면으로 underscore는 브라우져에서도 사용할 수 있고 server단에서도 별 이슈없이 사용할 수 있다. 사실, underscore는 node module들이 제일 많이 의존하고 있다. 지금 말한건 그렇다. underscore의 활용에 대해서는 겉만 살짝 긁은 정도다.
Microsoft가 며칠전 typescript를 발표했다. 아마 CoffeeScript처럼 ECMA Script 표준에 본격적으로 뛰어들기 위한 포석이 아닐까 싶은데, 어찌되었건 현재로는 무려 major IDE(라고는 하지만 Visual studio)에서도 강력하게 지원하고, 사람들이 많이 쓰는 Sublime Text2, Emacs, Vim에서도 플러그인으로 지원된다. 심지어 며칠전에 추가했던 SyntaxHighlighter의 typescript 버전도 벌써 올라왔다. 여하튼 좋은지 아닌지는 일단 적당히 써본 다음에 판단할 수 있으니 발이라도 살짝 담궈보기 위해서 Language Specification 문서를 받아봤으나 읽기엔 너무 길어서 dictation 연습이나 할까 하고 소개 동영상을 보려고 시도했다...고 하지만 1분만에 포기하고 그냥 언급된 소스만 보면서 메모해놓은 것들을 정리해봤다.
typescript syntax summary
variable type (declared like scala)
// number, string, bool
// main.ts import t = module("target") console.log( (new t.target.Dog).bark() ) console.log( t.version() )
=>
1 2 3
(03:13:55) test seoh$ tsc main.ts -e bow wow v0.0.1
다른 소스를 보다보면 node.d.ts, jquery.d.ts같은 파일들이 있는데, declarations 옵션으로 컴파일을 하면 c/c++의 header와 같은 개념으로 decoration typescript(d.ts) 파일이 생성된다. 예를들어 위에 있는 target.ts를 컴파일하면
1 2 3 4 5 6 7 8
(03:50:16) test seoh$ tsc --declarations target.ts (03:50:23) test seoh$ cat target.d.ts export module target { export class Dog { public bark: () => string; } } exportfunction version(): string;
처럼 선언만 남게 된다.
요즘 만지작거리고 있는 스칼라와 문법이 흡사해서 재미있기도 하고, module, class 개념으로 큰 프로젝트에서 분업할 때 편하긴 할 것 같은데... 아직 어디에 써야할지는 감이 안온다. 다른거 만지다보면 누군가 이런저런 토픽을 던저줄테니 일단 받아먹을 준비 중.
* 위에서 언급된 소스들은 module 부분을 제외하고 Microsoft의 동영상 소개에서 가져온 내용이니 해당 소스들에 대한 권리는 MS에게 있습니다.
"인사이트가 PDF 서비스를 시작합니다." 한국에서 최초로 DRM-free의 eBook을 출간한 회사가 '인사이트'가 아닐까. 4월 18일 저 글이 올라온 이후로 현재까지 인사이트에서는 인사이트 eBook에서 11권의 책을 9800원(뽀모도로 테크닉)~27000원(파이썬 완벽 가이트)를 PDF로 판매하고 있다. 어디 한 플랫폼에 종속되는 것을 싫어해서 그때까지 eBook을 구매한 적이 없었는데 인사이트의 이 판매를 보고 반가워서 응원도 할 겸 이벤트(종이책을 구매하는 사람에게 일정기간동안 파이썬 완벽가이드를 27000->14000으로 할인)도 하는 겸 구매했던 것과 리팩터링 워크북을 포함해 2권을 구매했고 Closure나 Ruby 책도 고민 중에 있다. 그러던 차에 오늘 검색 중 반가운 소식을 들었다. IT서적 전문의 다른 출판사인 한빛미디어에서도 DRM-free eBook을 판매하기 시작했다는 소개페이지를 발견했다.
IT말고 다른 분야에서도 DRM-free가 나왔으면 좋겠다는 생각도 들었지만 어쨌거나 보는 책의 반 이상, 아니 대다수가 IT관련 책이니 나에게는 좋은 일. "유지보수하기 어렵게 코딩하는 방법: 평생 개발자로 먹고 살 수 있다"라는 무료책을 비롯하여 현재 5권을 판매중이며 가격은 9900원(무료와 자바...를 제외한 나머지 세 책들)~11000원(자바 개발자를 위한 함수형 프로그래밍)로 인사이트에 비해 비교적 저렴한 편이나 대체로 얇은 책들 위주. 여하튼 굉장히 주관적이고 비논리적인 시각으로 특징을 비교해보자면
인사이트
주로 기초 서적
(페이지 대비) 저렴한 가격
레퍼런스 북 위주라 두꺼운 책들
출간본 그대로의 모습
작은 폰트
좌/우 페이지의 좌/우 여백이 다름
구매시 불편함
하루 2번 배송
only 무통장입금
한빛미디어
time to market 같은 책들
"핵심적인 내용을 빠르게 전달하기 위해 조금 거칠지만 100page 내외의 전자책 전용" - 소개 페이지 中
eBook에 맞춘 편집
큰 폰트
(비교적) 적은 여백, 넓은 행간
책보다는 포스팅이나 매거진 느낌
"보완되고 발전된 노하우가 정리되면 구매하신 분께 무료로 업데이트" - 소개 페이지 中
써놓고 나니 책 가격을 페이지에 비례해서 책정한다는건 무척 어리석은 일이지만 모든 책을 읽어볼 수 없으니 그냥 공개된 정보만 훑어보다가 들었던 생각이다. 어느 쪽이 더 좋은가? 어디가 더 많이 팔릴까? 라고 잠깐 생각을 해봤는데 둘 다 썩 좋은 질문은 아닌거 같다. 단순히 '편집'만 가지고 이야기를 하자면, 여백이나 행간은 한빛쪽이 확실히 읽기 좋고 폰트 자체는 인사이트쪽이 읽기 좋고, 작은 폰트는 아이패드류나 데스크탑에서 읽기 편하고 큰 폰트는 5"~7" 정도에서 읽기 편하다. (그 이하의 화면 크기는 PDF 자체가 읽기 불편하다.) 책 종류 자체도 인사이트는 기본서(혹은 레퍼런스)같은 느낌이고 한빛은 실용서(혹은 노하우)같은 느낌이다. 둘 다 필요한 종류의 책들.
비교 이외의 한가지 토픽을 더 던지자면, DRM-free에 대한 정보가 더 없나 검색하다가 "DRM으로부터의 해방, 영원히"라는 글을 읽었다. 사실 eBook이 유행하기 전에도 어둠의 경로로는 만화/소설/잡지 등의 스캔이 떠돌고 있었고 여전히 그렇다. 이런 상황에서 DRM이 없어지면 '무단 복제'가 더 빈번해질까? 판매량이 더 감소할까? 저 링크 속의 글에 있는 "이해할 수 없는 것은, 책 판매량은 줄지 않았다는 것이다. 사실, 판매량은 그 해에 살짝 올라갔다."라는 말이 한국의 실정에도 적용될 수는 없더라도 그 의미를 같이 하지 않을까. 그렇기에 인사이트나 한빛미디어에서도 이런 도전을 하고 있는 것이겠고, 그것을 응원한다 :)
Caike souza는 CoffeeScript의 어떤 점들이 좋은지, 왜 이게 프로젝트에서 쓰일만한지에 대해 보여줄 것이다.
커피스크립트는 최근에 만들어진 인기있는 언어다. 커피스크립트는 자바스크립트의 강력한 객체 모델을 훨씬 간단한 문법으로 사용할 수 있을 뿐만 아니라 이미 존재하는 특징들 또한 쓸 수 있다. 여전히 커피스크립트가 배울만하다고 생각한다면, 내 대부분의 프로젝트에서 왜 쓰고 있는 10가지 이유들을 보자.
1. 깔끔한 문법
C언어의 문법에서 강하게 영향을 받은 자바스크립트처럼이 아니라 커피스크립트의 문법은 루비와 파이썬에서 영향을 받았다. 파이썬과 루비 코드를 본 적이 있으면 커피스크립트의 문법 몇개가 친숙할 것이다. 세미콜론으로 문장을 구분하지 않고 줄 단위로, 메소드의 호출이나 조건을 쓰는데 괄호는 옵션, 공백에 민감하고, 이 모든건 훨씬 쉽게 읽기 위한 문법이다.
1 2
message = 'Hello World' sayHello message
2. 자바스크립트의 좋은 부분만 생성
자바스크립트에는 알려진 단점들이 있다. 커피스크립트는 항상 자바스크립트의 장점만을 생성하도록 최선을 다할 것이다. 한가지 예로 커피스크립트로 생성되는 모든 자바스크립트 파일은 자신의 영역(scope)를 가진다. 익명 함수로 코드를 감싸면 개발자가 이름이 충돌(naming collision)하지 않게 방지하고 전역 네임스페이스를 섞이지 않도록 해준다. 간단한 HelloWorld를 자바스크립트로 생성시킨건 다음과 같다.
위의 예시에서 sayHello 함수는 익명 함수 내에서만 가능하고 전역 네임스페이스에는 추가되지 않는다.
3. Fat Arrow
자바스크립트는 진짜 강력하고 유연한 언어다. 그러나 때론 이 특징들이 개발자가 이때문에 추가적인 코드를 쓰도록 요구한다. 커피스크립트에서는 언어 내부에서 이런걸 해결한다.
다음 예제에서 우리는 callback 함수의 내부에서부터 커피 객체의 context로 접근한 필요가 있다. 자바스크립트 개발자들 사이에서 널리 사용되는 규칙으로, callback 함수 외부에서 객체의 context 내부 변수로 값을 전달한다, 그래서 callback 함수로부터 참조가 되고 있어야한다, 다음 예시처럼
1 2 3 4 5 6 7 8 9
var coffee = { isFull: true, watchDrink: function(){ var that = this; $('.drink a').on('click', function(){ that.isFull = false; }); } };
이런 방법을 커피스크립트로 변환한다면 여전히 가능하다.
1 2 3 4 5 6
coffee = isFull: true watchDrink: -> that = this $('.drink a').on'click', -> that.isFull = false
그러나 커피스크립트는 뚱뚱한 화살표 연산자(Fat Arrow Operation, 그냥 Fat Arrow는 원어로 표기해야겠다)로 똑같은걸 더 효과적으로 보여주는 방법이 있다. 이전의 커피스크립트 코드에서 이제 Fat Arrow를 쓰면 다음과 같다.
커피스크립트 클래스에서 객체를 만드는 방법은 자바스크립트에서 new 연산자를 통해 생성자 함수를 호출해서 만드는 방법과 완전히 똑같다.
1
frenchCoffee = new Coffee('French')
전망
자바스크립트의 창시자인 Brendan Eich처럼 자바스크립트 커뮤니티의 주요한 사람들이 커피스크립트 문법 표준화를 하고 있다. class 키워드를 통한 prototype 상속 같은 것들, @ 연산자나 =>같은 것들은 실제로 몇년 안에 자바스크립트에 들어갈 것이다.
"커피스크립트의 class, super, @같은 문법적인 좋은 것들로 prototype의 상속을 표준화시키려고 열심히 만들고 있다"
- 자바스크립트의 창시자, Brendan Eich
9. 커뮤니티 전파
RoR 3.1 버전부터 커피스크립트를 out-of-the-box(바로 쓸 수 있게끔) 지원하기 시작했다. 파이썬이나 PHP같은 다른 언어의 Web Framework들은 컴파일 단계를 지원하는 서드파티 라이브러리들을 갖고 있다. 또 많은 유닛 테스트 프레임워크들이 커피스크립트를 지원하기에 커뮤니티들이 활발히 포용하고 있다.
10. 배우기 좋은 자원들
커피스크립트 공식 웹사이트는 훌륭한 문서와 바로 돌려볼 수 있는 예제들을 제공한다. 언어가 어떻게 만들어졌는지 자세하게 파볼 사람들을 위해 소스코드 또한 웹사이트에 잘 문서화되어있고 읽을 수 있다. 더 배울 수 있도록 많은 온라인 강좌, 책, 전자책, 블로그 포스팅들이 있다. CodeSchool.com은 입문할 수 있는 무료 커피스크립트 강좌가 있는 곳이다.
이것들 덕분에 커피스크립트에 더 관심을 갖게 되었다. 이 글이 커피스크립트가 배울 가치가 있는 언어인지에 대한 토론하는데 도움이 되길 바란다.
사전에 등장하고 길이가 같은 두 단어가 주어졌을 때, 한 번에 글자 하나만 바꾸어 한 단어를 다른 단어로 변환하는 프로그램을 작성하라. 변환 과정에서 만들어지는 각 단어도 사전에 있는 단어여야 한다.
[실행 예]
input : DAMP, LIKE
output: DAMP -> LAMP -> LIMP -> LIME -> LIKE
[사전 데이터]
네 글자 단어 - word4
다섯 글자 단어 - word5
[심화 문제 - 풀지 않아도 됩니다]
심화문제 1: 가장 적은 수의 단어를 써서 변환하도록 프로그램을 작성해봅시다.
심화문제 2: 가장 많은 수의 단어를 써서 변환하도록 프로그램을 작성해봅시다. 단, 변환 과정에서 같은 단어가 두 번 나오면 안됩니다.
가장 단순한 접근.
모든 데이터를 메모리에 올려놓고, 앞에서부터 한글자씩 대입해서 사전에서 검색해보고 있으면 치환. 목적지에 도착할 때까지 반복. 혹시 한바퀴(문자열 길이)를 돌 때까지 치환할 단어가 없으면 찾을 수 없다고 판단. 일종의 Greedy로 답을 찾을 수는 있지만 가장 빠른 답인지 보장하지는 못한다.
# synonym.coffee v = process.argv if v.length < 5 process.exit -1 n = parseInt v[3] src = v[4].toLowerCase() dst = v[5].toLowerCase()
data = require('fs').readFileSync './word' + n + '.txt' data = data.toString().split '\n'
if data.indexOf(dst) is-1 console.log 'dst does not exist in data text' return0
console.log src while src isnt dst __ = src for i in [0...n] temp = src.substring(0, i) + dst.charAt(i) + src.substring(i+1,n) if __ isnt temp and data.indexOf(temp) isnt-1 src = temp console.log "-> #{src}" if src is dst thenreturn if __ is src console.log "IMPOSSIBLE" return0
그리고 출력값
1 2 3 4 5 6
$ coffee synonym.coffee 4 damp like damp -> lamp -> limp -> lime -> like
소스에서는 생략했지만, 6회(두번째 루프) 만에 찾았다.
Shorted Path나 Longest Path를 찾기 위해서는 edge에 index 정보를 기록하는 graph를 만들어야할꺼 같은데, 그러려면 모델링하는데만 O(n^2)만큼의 시간이 걸린다.
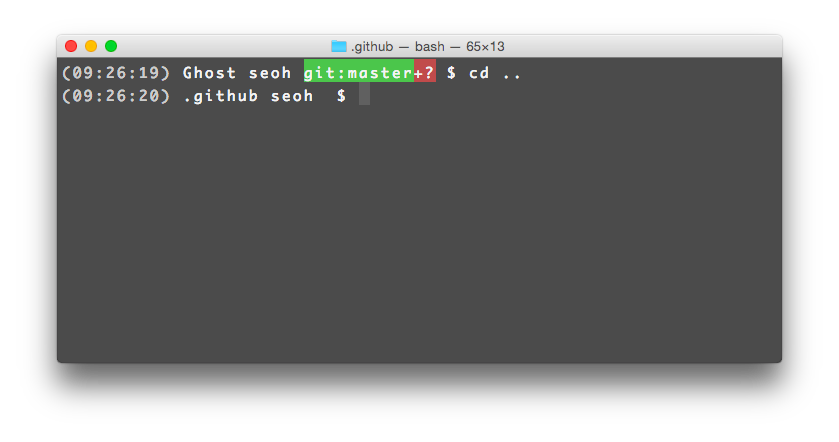 위와 같이 전/후가 변경되었다.
위와 같이 전/후가 변경되었다. vs 함수형 프로그래밍(한빛미디어)")
 vs 함수형 프로그래밍(한빛미디어)")