어제 @wesbos가 .bind()를 사용한 querySelector 단축에 대한 js 소스를 캡쳐한 트윗을 올렸다.
1 2 3 4
// 선택된 첫번째 엘리먼트 - $('input[name="food"]') var $ = document.querySelector.bind(document); // 선택된 엘리먼트들의 배열 - $('img.dog') var $$ = document.querySelectorAll.bind(document)
여기에 @paul_irish가 비슷한 컨셉으로 이벤트 등록까지 할 수 있는 bling.js를 리플로 남겼다.
let $ = ::document.querySelector; let find = Element.prototype.querySelectorAll; let each = Array.prototype.forEach; let on = Node.prototype.addEventListener; // 이하 생략
생소한 문법이 등장했다. ::는 어떤 의미일까?
예전에 봤던 reactjs로 ES6를 접한 사람들이 하는 오해에 대한 글, ES6 Gotchas가 생각났다.
이런 식으로 this.handleClick을 그대로 넘기는게 아니라 자동으로 bind해서 넘겨주는걸 react에서 해주기 때문에 사람들이 오해하기 쉽다는 뜻이다.
babel에서는 (소위 ES7이라 부르는)실험 기능을 활성화할 수도 있는데, 그 중 데코레이터에 autobind decorator를 붙일 수도 있다.
@autobind를 메소드 혹은 함수 위에 붙이면 react처럼 bind해주는 기능을 한다. 그런데 이게 마음에 안 찼는지 함수 Bind 문법이라는 제안이
나왔고, babel에도 추가되었으며 자세한 설명된 포스팅도 올라왔다. 위에 'ES6 Gotchas' 댓글에서 예제 소스를 빌려오자면,
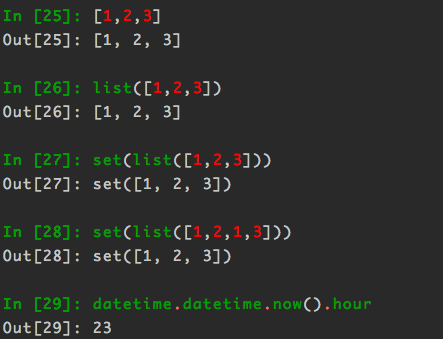
::a.b는 a::a.b와 같다.
a::b.c는 b.c.bind(a)와 같다.
그러므로 ::a.b는 a.b.bind(a)와 같다.
이제 다시 처음 소스의 ::document.querySelector를 풀어보자면 document.querySelector.bind(document)라는 것을 알 수 있다.
ES6/ES7(이제는 ES2015 or after라고 부르지만)에 대한 이야기를 자주 하는 이유는 재미있고 내가 관심 있는 분야라서도 그렇지만,
이런 기술들은 나 혼자 편하다고 해서 쓸 수 있는 것이 아니다. 같이 일하는 사람들이 필요성에 대해 공감하고 익숙해야 쓸 수 있다.
그래서 보다 많은 사람들이 관심을 가지고 익숙해졌으면하는 바람이 있다. (물론 나는 현재 무직이라 같이 일하는 사람이 없지만 나중을 위해)
JavaScript라는 언어의 문법 자체는 심플한 편이지만, 거지같은 실행환경 때문에 this가 뭐냐 언제 결정되느냐는 질문을 하도 많이 받아서
"var that = this" 같은 자바스크립트 스코프에 대한 이해라는
StackOverflow의 답변을 번역해 글을 쓴 적도 있다. 어차피 웹이라는 거대한 플랫폼에서 자유로운 개발자는 많지 않고, 발을 디딘 사람들 중 대부분은 프론트를 한 번쯤 만지게 된다.
피할 수 없다고 즐기는 건 변태지만, 최대한 생산성을 높여서 괴로움을 줄이길 바란다.
edX에서 Spark로 빅데이터 입문(Introduction to Big Data with Apache Spark)을
듣고 있다. UC Berkeley의 Anthony Joseph 교수가 진행하는 수업으로, 실제 데이터를 가지고 과제
4개를 진행하면서 Spark로 빅데이터 분석하는 방법을 배운다고 하는데, 수업 난이도 자체는 높지 않다.
대상은 Python 경험자로 분산 컴퓨팅/Spark에 대한 지식은 없어도 된다고 되어있다. 환경 설정도
Jupyter(IPython Notebook의 새 이름)와 PySpark가 이미 세팅된 환경을 Vagrant로 제공해주는데,
Vagrant의 이름만 알고 있는 정도였지만 동영상에서 OS별로 제공하는 동영상을 보고 따라하는데 무리는 없었다.
실습은 노트북 파일에서 비어있는 부분을 채우면서 진행하면 되는데, 의도에 대한 설명은 코드 위에 충분히
자세하게 되어있고 단계별 진행이다보니 정확히 읽지 않아도 코드를 보면서 따라가면 유추가 가능하다.
단순히 유행어(Buzzword) 이상으로 Big Data나 Spark에 대해 배워보고 싶은 사람들에게 추천할 겸,
몇달 뒤에 잊어먹을 나 자신을 위해서 기록을 남겨본다.
사람들이 크롬하면 생각하는 대표적인 장단점으로는 강력한 확장과 강력한 메모리(흡수)가 있다.
아무 이유 없이 수많은 프로세스와 수많은 메모리를 잡아먹지는 않을테니 그 트레이드오프가 내부적으로는
앞으로 쓸 이야기와 관련있을 수도 있지만, 내가 크롬을 쓰는 이유는 (직접적으로)이것들 때문은 아니다.
일단 내 패턴에서 브라우저의 기본 조건은 다음과 같다.
죽는 건 상관없지만 죽은 뒤에 탭 목록이 유지될 것
패턴이라는 게 별것 없다. 트위터, RSS, 뉴스레터에 올라온 링크들을 브라우저에 최대한(약 50개)으로
올려놓고 빠르게 훑어본 뒤 필요 없다고 판단된 것들은 닫고 정독할 것들을 쌓아둔다. 예전에는 그냥 닫거나
포켓에 넣거나 둘 중 하나였는데, 포켓이 반응속도가 느려진 뒤로 포켓을 거치지 않고 그냥 브라우저에
띄워놓고 있다. 다양한 곳에서 하루에 세 자리 단위의 링크들을 띄우고 정리하다보니 어디까지 읽었는지,
어떤 것을 정독하려고 판단했는지의 목록이 사라지면 그것을 다시 복구하는 것만 해도 경험상 두세 시간 이상은
걸리게 되니 탭 목록이 사라지는데 매우 민감해졌다. 물론 공식적으로 사파리/파이어폭스도 탭 목록을
유지해준다.
사파리에서는 다시 열었을 때, 마지막 세션에서 모든 윈도우를 다시 자동으로 열어주는 옵션도 있고, 혹여
저 옵션을 선택하지 않았거나 비정상적으로 종료되었을 때 마지막 세션의 모든 윈도우를 다시 열게 해주는
기능이 존재한다. 그리고 Session 등 주기적으로 세션을 백업해두는 확장도 존재하긴 한다. 다만,
비정상적으로 종료당하는 일이 그리 많지는 않은데 그럴 때 앞에서 언급한 기능들에서 제대로 목록을
살려주는 경우가 별로 없다. 맥에서 가장 미려하고 반응속도도 좋은 사파리라 사파리나 OS X의 메이저
업데이트때마다 항상 재도전을 하고 있지만 항상 실패했다. 물론 10.11이나 Safari 9이 나오면 또
도전할 예정이다. 하지만 그리 큰 기대를 하진 않는다.
파이어폭스도 마찬가지지만 비정상 종료의 모습이 약간 다르다. 사파리는 "뿅! 사파리가 사라졌습니다"
하면서 갑자기 튕긴다면, 파이어폭스는 갑자기 "나 죽어어어어어어어어"하면서 CPU 점유율이 100%를
넘어가며 주변에 민폐를 끼쳐서 어쩔 수 없이 강제종료하게 만든다. IE 6, 7 시절부터 쓰기 시작해서
크롬으로 넘어가기 전에 메인으로 쓰다가, 크롬이 지나치게 무거워져서 돌아간 게 20대 후반 버전이었던
것으로 기억하는데 파이어폭스도 그때부터 메이저 버전때마다 도전했지만 항상 저런 증상 때문에 실패했다.
Session Manager 등 확장들을 찾아봤지만 평소에도 느리게 만들고 구동시간을 느리게 만들 뿐이었다.
사파리가 다른 두 브라우저에 비해 개발도구의 기능은 매우 떨어지나, 메모리/배터리 효율 면에서
비교하기 어려울 정도로 좋다는 장점이 있고, 파이어폭스는 개발도구로써 최신 기술이 가장 먼저 들어가고
Event listeners popup처럼 다른 브라우저에서 찾기 힘든 편리한 기능 등이 있다.
저 브라우저들이 내 머신들에서만 같은 문제를 발생하는 것일 수도 있고, 하루에 몇백 개의 링크를 훑어봐야하는
사람이 많지도 않을테니 누군가에게 동의를 구할 수도 없고 그럴 생각도 없는 이유지만, 이것이 내가 크롬을
쓸 수 밖에 없는 이유다.
RSS에 글이 뜸해질 때는 Coven을 보는데, Hacker News, /r/programming
(Reddit의 프로그래밍 서브레딧- 게시판 개념) 등 사이트 4개의 추천 상위 글을 실시간으로 가져오는 곳이다.
다른 곳에도 공유하긴 했지만, 여기 올라온 글 중에서 흥미로운 ES의 제안(제안-초안-후보-마감의 단계 중 첫 번째)에 해당하는 것 2개를 소개하려고 한다.
ES5의 "use strict"를 포함하는 개선된(빡쎈) 버전이다. V8의 경우 예측할 수 있는 경우에는 최적화된 컴파일러를, 아닌 경우에는 일반 컴파일러를 실행한다고
되어있는 글이 있었는데, 다른 구현체들의
정확한 internal은 잘 모르겠지만 컨셉 자체는 다른 곳에도 적용가능해보인다. 다시 말해서, 프로그램 흐름과 객체 상태를 제약해서 유지보수를 편하게 하고
성능을 좋게 한다는 아이디어에 대한 구체적인 제약들이다. 대표적으로 var와 delete를 금지하는 문법상 제약이 있다. var를 금지하는 대신 let을
사용해서 lexical scope의 범위를 줄여서 컴파일러나 사람이 생각해야하는 양을 줄이겠다는 것으로 보인다. 그리고 delete를 금지하면 객체의 형태가 고정
(seal)되어 형태에 대한 정보를 재사용하고 예측가능해진다.
(참고, ES6의 Object.freeze와 Object.seal의 차이에 대한 답변)
ES6의 Generator와 ES7의 async/await를 합치면 비슷한 구현은 가능하지만, async generator의 경우에 IO에는 적합하지만 Push(Event, WebSocket)
등에는 적합하지 않는다. 즉 async는 producer를 observable은 consumer를 만들 때 적합하다(하지만 이해를 잘못한 것인지 슬라이드에는 반대로 되어있다).
사실 이게 들어갈 확률은 매우 적어 보이지만, 요즘 듣고 있는 Coursera의 reactive programming에서
Rx에 대한 내용이 나오다 보니 그쪽으로 관심이 생겨서 RxJS도 써보고 싶은데 마침 이 제안을 발견해서 기억에 남았다.
ps 1, 이것들 말고도 hn/reddit에 추천 상위로 올라온 게 더 있지만 재미가 없었는지 키워드도 기억나지 않는 게 많다.
ps 2, 흥미로운 것들을 발견하면 실시간으로 트위터에 올리고 있다. @devthewild
함수형 프로그래밍에서 기본개념은 조합(composition) 이다. 간단히 설명해서, 단순한 것들을 엮어서 더
복잡한 것을 만들 수 있고 그 결과를 다시 엮어서 더 복잡한 것을 만들 수도 있다. 함수의 의미나 리턴값이
무엇인지만 알고 있으면 조합으로 무엇이든 만들어낼 수 있다.
Node.js를 써봤으면 아래와 같은코드를 본 적이 있을 것이다.
1 2 3 4
fs.readFile('...', function (err, data) { if (err) throw err; .... });
위의 코드는 전형적인 CPS(continuation-passing style) 함수이다. fs.readFile이라는 CPS
함수는 계속(continuation) 진행될 콜백을 추가 파라미터로 받는다. 이 CPS가 끝나면 호출한 곳에 값을
반환하는게 아니라 계속 함수, 콜백에 계산 결과를 넘겨준다.
나는 콜백을 쓰는걸 꺼리진 않는다. 사실 콜백은 부수효과를 표현하거나 이벤트 알림같은 것을 다룰 때
훌륭하다. 그렇지만 그걸로 흐름을 관리하기 시작하면 함정에 빠진 것이다. 왜냐면 조합할 수 없기 때문에.
자, 생각해보자. "위에 나온 함수의 **표기(denotation)**나 리턴값은 무슨 의미일까?" 답은
undefined이다. undefined라는건 테스트할 때 실제로 undefined인지 확인하는 용도 이외에는 쓸
데가 없다.
콜백 안에서 다른 실행 흐름으로 넘어갈 때 일방통행이라는게 문제다.
물리학에서 유명한 블랙홀처럼 콜백을 생각해보자:
블랙홀은 수학적으로 정의된 지역이다. 강한 인력이 작용하거나, 어떤 티끌이나 전자기적 파장조차
빠져나갈 수 없는
그 중에서도
어떤 빛도 반사하지 않는 등 블랙홀은 많은 부분에서 이상적인 검은 물체처럼 작용한다.
콜백 함수 또한 흐름에서의 어떤 것도 반사하지 못한다.
나중에 첫번째 콜백에 들어갈 때 다른 콜백 스타일 함수를 쓸 수 있는데, 그때는 두번째 흐름을 잃게
되고 다른 구멍에 빠지게 된다. 콜백을 쓰면 쓸 수록 지옥에 빠지게 된다.
그럼 블랙홀에 빠지지 않고 코드를 진행할 수는 없을까?
답은 조합이다. 하지만 조합을 사용하려면 일단 CPS 함수가 어디로도 돌아갈 수 없다는 사실을
알아야하고, 함수로부터 뭔가를 받아와야한다. 그러니 어떻게든 함수가 뭔가를 반환하게 만들어야한다. 어떤
값이 반환될까? 이게 이 글의 동기이다.
이미 자바스크립트에서의 해답을 알고 있을 수 있다. 하지만 계속 이 글을 읽도록, 강하게, 추천한다.
지시적인(즉 함수형) 생각의 힘을 보게 될 것이고, 깔끔하고 간결한 해답을 어떻게 사용할지 보게 될 것이다.
future로 입문
파일 읽기, 네트워크 요청, DOM 이벤트, 이런 함수들의 공통점은 뭘까?
이 함수들은 즉시 완료되지 않는 것들이다. 즉, (보통 함수들을 다루는 식으로는) 현재 프로그램
흐름에서 저 함수들이 완료될 때까지 기다릴 수 없다는 뜻이다. 그래서 _future_를 설명할 것이다.
그래서 특별한 반환 타입, 나중에 결과를 만들어준다고 명시하는 Future를 만들어보자. 요점은 다른
함수들로 넘길 수 있는 1등급 클래스 값을 사용하는 것이다.
Future는 무슨 의미일까? 특정 시간(0이 될 수도 있다) 후에 발생할 것이라고 명시해놓은 값이다.
그 시간은 우리가 x초 후라고 말하는 것처럼 명시적인 시간이 될 수도 있지만, Future 2개가 완료된 후
혹은 Future 하나가 완료된 뒤 다른 Future 완료될 때처럼 상대적인 개념일 수도 있다.
여기서 중요한 점은: Future의 결과는 항상 불변값이다.
즉, 완료 값을 어떤 방법으로든 변경할 수 없다. 이 제약으로 구현 뿐만 아니라 의미론에 대한 추론도
간단해진다.
Future는 일회용의 간단한 상태머신처럼 구현될 수 있다. 이 머신은 대기 로 시작했다가 완료 가 된
후에 멈춘다. 한번 완료되면 계속 완료상태에 고정된다.
내부적으로 Future는 콜백에 여전히 의존하고 있지만, 그 콜백들이 컨트롤 흐름 매커니즘을 방해하지는
않는다. 대신 올바른 목적으로만 사용된다, 이벤트 알림.
Future의 가장 간단한 예제로 어떤 값으로 즉시 완료시켜보자. 그 역할을 unit이란 메소드를
만들어보자.
1 2 3 4 5 6 7 8
// unit: Value -> Future<Value> Future.unit = function(val) { var fut = new Future(); fut.complete(val); return fut; }
logF( Future.unit('hi now') );
코드에 대해 간단히 설명하기 위해 타입 표기(type annotation) 를 사용했다.
unit: Value -> Future<Value>를 풀어보면 1- unit은 함수고, 2- 제네릭 타입 Value를
입력으로 받으며, 3- 제너릭 타입을 가진 Future 인스턴스를 리턴한다. 여기서 타입 정보는 중요하지
않으므로 Value라는 제너릭은 신경쓰지 않아도 된다.
다음 예제는 특정 시간이 지나고 완료되는 값이다.
1 2 3 4 5 6 7 8 9 10
// delay: (Value, Number) -> Future<Value> Future.delay = function(v, millis) { var f = new Future(); setTimeout(function() { f.complete(v); }, millis); return f; }
logF( Future.delay('안녕, 이건 5초 걸린다', 5000) );
delay의 결과는 주어진 값만큼의 시간이 지난 뒤에 완료되는 Future다.
readFile 예제로 돌아가서, 이제 CPS 함수 대신에 Future를 리턴하는 함수를 사용할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
var fs = require('fs');
// readFileF: (String, Object) -> Future<String> functionreadFileF(file, options) { var f = new Future(); fs.readFile(file, options, function(err, data) { // 에러는 잠시 후에 다루겠다
readFileF의 결과는 인자로 받은 파일 이름의 내용을 잡고 있는 Future가 된다.
Future 다루기: 첫번째 게스트
Future를 결과적으로 함수의 결과를 잡고 있는 마법 상자처럼 생각할 수도 있다.
뭔가 쓸모있는 것을 하려면 Future 타입에서 쓸모있는 연산들을 제공해야한다. 그러지 않는다면
필요없이 또 다른 undefined를 만든 것과 다를 바 없다.
그러면 어떤 연산을 Future에서 제공해야할까?
Future 상자에서 잡고 있는 값에 어떤 연산을 하고 싶을 때 (function map을 줄인)fmap을 호출할
것이다.
fmap의 예제를 보자. 여기서 Future는 텍스트 파일의 내용을 잡고 있고, 이 내용의 길이를 계산하려고
한다.
1 2 3 4 5
var textF = readFileF('test.txt', {encoding: 'utf8'});
// fmap: (Future<String, (String -> Number)> -> Future<Number>) var lengthF = textF.fmap( text => text.length ); logF( lengthF );
lengthF의 뜻은 인자로 받은 Future가 잡고 있는 파일 내용의 길이를 잡고 있는 Future다.
일반화를 해보자면, fmap은 인자를 둘 받는데, 하나는 값을 잡고 있는 Future고 하나는 일반값을
다루는 매핑 함수다. 입력으로 받은 Future의 결과물에 매핑 함수를 적용한 결과를 잡고 이는 Future가
결과로 나온다. 받은 Future와 결과 Future는 둘 다 동시에 완료된다.
Future.prototype.fmap = function(fn) { var fut = new Future(); this.ready(function(val) { fut.complete( fn(val) ); }); return fut; }
현재 Future가 완료되었을 때 결과로 나온 Future도 완료된다. 그 때 매핑 함수를 적용시킨다.
위의 예제에서는, 파일 내용을 잡고 있는 Future를 내용 길이를 잡고 있는 다른 Future로 변이시켰다.
어디서 들어본 말 같지 않은가? 잘 알고 있는 자바스크립트 Array의 map 메소드와 꽤 비슷하다.
실제로 정확히 같은 개념이다.
Array 타입은 여러 값들을 잡고 있는 박스다
Future 타입은 완료될 값을 잡고 있는 박스다
Array.map(...) 은 Array 박스 안의 값들을 변이시켜서, 변이된 값들을 잡고 있는 다른 Array 박스를 돌려준다
Future.fmap(...)은 Future 박스 안의 값을 변이시켜서, 변이된 값을 잡고 있는 다른 Future 박스를 돌려준다
Array와 Future 타입 둘 모두 포함되는 Functor라는 첫번째 게스트가 등장했다. 일반 함수를 하나
받아서 안에 무엇을 가지고 있든 그것이 변이된 결과를 표현하는 다른 인스턴스를 만들어내는 타입이다.
다른 타입을 감싸는 컨텍스트처럼 작동할 수 있는 타입이고
내부에 있는 것을 일반 함수에 적용시킬 수 있다면
Array와 Future가 아니더라도 그게 무엇이든간에 그 타입을 Functor라고 부를 수 있다.
이제 Future를 다른 Future로 매핑할 수 있다. 이제 일반값을 다루듯이 Future를 직접적으로 다루는
함수를 만들 수 있다는 뜻이다. textF.fmap( c => c.length )처럼 호출하는 대신에 Future를
직접 다루는 lengthF라는 특별한 종류의 함수를 만들 수도 있다.
lengthF를 lift된 함수라고 부른다. Functor같은 _박스 타입_을 다루는 함수를 lift한다는
것은 일반값을 다루는 함수를 박스 타입을 다루는 함수로 만든다는 뜻이다. 여기에서는 문자열을 다루는 함수
length(String)를 lift해서 Future를 다루는 함수lengthF( Future<String> )로 lift했다.
비동기 실행을 일반 함수 실행처럼 만들어주는 간단한 추상 함수다. 위에서 lengthF( readFileF('...') )는
readFileF와 lengthF를 조합해서 비동기 연산을 현재의 흐름을 떠나지 않고 실행할 수 있다.
인자를 여러개 받는 함수는 어떻게? (두번째 게스트?)
질문에 대답하기 전에 잠시 기초지식에 대해 생각해보자: Future 박스가 잡을 수 있는 타입에는 뭐가
있을까? Future는 모든 타입에 대해 같은 의미를 가질까?
Future<String>의 뜻은 명확하다: 시간이 지난 뒤에 문자열 타입의 값이 발생한다는 뜻이다. 다른
타입들에 이 의미를 확장할 수 있을까? 숫자, 객체, 배열? 그럴듯... 그럼 Future 자체에 대해서는
어떨까? Future<Future>는 무슨 뜻일까? 그러니까 Future의 Future는?
보고 바로 이해할 수 있도록, 디렉토리를 보고 첫번째 파일의 내용을 읽는 간단한 예제를 만들어보자
(간단히 생각하기 위해 내부에 다른 디렉토리가 없다고 가정한다).
Node.js에서는 비동기 함수 fs.readdir을 통해 디렉토리 속 파일들 이름의 배열을 가져올 수 있다.
먼저 이걸 Future식 함수로 만들어보자.
1 2 3 4 5 6 7 8 9 10
// readDirF: String -> Future< Array<String> > functionreadDirF(path) { var f = new Future(); fs.readdir(path, (err, files) => { // 기다리면 곧 실행된다 if(err) throw err; f.complete(files); }); return f; }
개념상으로는 위에서 독립적인 두 연산을 _이어서_하는 것인데, readDirF에서 나오는 파일 이름의
배열을 readFileF에 넘겨준다.
여기에서 두번째 게스트가 등장하는데, Future를 Functor라고 부를 수 있는 것처럼 Monad라고 부를
수도 있다. 순서대로 연산할 수 있는 방법에 대한 개념이다. 위에서 flatMap에서처럼, 이전 단계에서의
결과를 다음 단계로 넘겨서 여러 함수를 연이어 연산할 수 있다.
Functor처럼 Monad도 많은 사용법이 있는데, 기술적으로 모든 모나드는 다음을 만족한다.
일반값을 Monad식(Monoadic) 값 으로 lift하는 방법: 예를 들어, Future.unit은 일반값을 Future로 만든다.
연이은 연산 2개를 이어서 실행하는 방법: Monad는 연산을 이어서 실행하게 해주는 방법이 포함된다. 위에서 flatMap은 그냥 Future 하나만 만들고 다음으로 넘어가는게 아니라, 앞의 Future가 끝날 때까지 기다렸다가 넘어가는 방법이 들어있다.
위에서 2개의 다른 연산(fmap과 flatten)으로 두번째 인터페이스(flatMap)를 만들 수 있다는
것을 확인했다. fmap 함수를 정의하는 Functor라면 이중 구조를 단순화시켜서 합치는(flatten) 연산이
필요해진다.
이제 처음의 질문으로 돌아가보자, Future들 여러개를 받는 함수를 어떻게 lift할 수 있을까?
다시 파일 예제로 돌아가서, 디렉토리의 모든 파일 내용을 합치려면 이런 코드가 될 것이다.
이건 무슨 뜻일까? 입력받은 Future들이 잡고 있는 각 문자열들을 합친 것을 다시 잡고 있는 Future를
만들어준다. concatF는 입력받은 모든 Future들이 순서대로 처리되도록 기다려야하므로 결과로 나온
Future는 입력받은 모든 Future가 완료될 때 완료된다.
return (idnex < futArgs.length - 1) ? // 아직 마지막 Future 인자가 아니라면 bindArg(index+1, valArgs) : // 다음 인자를 flatMap에 넘기고 기다린다 Future.unit( fn.apply(ctx, valArgs) ); // 끝까지 오면 모은 완료값들을 함수에 넘긴다 }); } } }
lift에서는 lift2의 패턴을 재활용했다. 인자가 몇개 들어올지 정확히 모르니 재귀를 통해 전체를
순회(iterate)하고, 완료를 기다렸다가 결과를 계속 넘겨서 모은다.(index번째의 Future를
기다렸다가 완료값을 저장하고, 모든 입력이 완료될 때까지 다음 Future 입력에 이 연산을 반복한다.)
마지막 Future까지 오면 함수를 실행하고 결과를 lift해서 리턴한다.
노트: 'Applicative Functor'라는 자료구조를 통해 n개 인자를 lift하도록 구현할 수 있지만,
그러려면 람다나 커리에 대한 설명을 해야하므로 오늘은 일단 생략하자.
에러 처리
위에서 fs.readFile의 에러값을 어떻게 뒀는지 다시 확인해보자.
1 2 3 4 5
functionreadFileF(file, options) { var f = new Future(); fs.readFile(file, options, function(err, data) { if(err) throw err; ...
실제로 작동하지 않는 코드다. 프로그램 흐름에서 떨어져서 실행중이므로 발생하는 에러를 잡을 방법이 없다.
위의 상황에서 에러는 상위로 전파되며 잡는 핸들러가 없어서 Node.js 전체 프로그램을 중단시킨다.
에러를 잡아 흐름을 고치려고 한다거나 의미있는 메시지를 사용자에게 전달하는게 필요할 수도 있다.
가능한 방법으로는 Future에 실패 의 개념을 붙여서 의미를 확장하는 것이 있다. 아직까지는 Future의
결과에 어떤 의미를 붙이지는 않았지만, 가능한 2가지 결과(완료 혹은 실패)로 Future를 생각해볼 수도 있다.
실패에 대한 경우가 포함되었는지 확인해보자.
resultF는 첫번째 요청이 성공할 때 'url1'의 내용을 잡고 있고, 실패할 때는 'url2'를
요청해서 그 결과를 잡고 있다는 뜻이다.
부수효과
합성해서 연산할 수 있는 방법에 대해 필요한 것들을 모두 다뤄보았다. 지금까지 다뤘던 함수들을 통해서
Future를 동기 연산을 할 때처럼 일반값으로 넘겨서 비동기 처리를 하게 해봈다.
하지만 연산들은 끝까지 도달해야 결과가 나온다. 부수효과가 필요한 연산들을 다뤄 볼 시간이다. UI를
업데이트한다거나 콘솔에 로그를 찍는다거나 데이터베이스에 저장을 한다거나.
ready와 failed 이벤트를 사용할 수도 있지만 좋은 방법은 아니라고 생각한다.
실제 어플리케이션에서 한 Future가 여러 자식 Future들을 가지고 그 Future들은 또 자식 Future들을
갖게 되는 트리같은 구조가 된다. Future하나가 완료돌 때 매핑된 Future들이 연쇄적으로 완료된다.
Future의 ready알림을 통해서 부수효과를 실행하려고 한다면 트리 내부에 있는 Future들 전체에
영향을 끼치게 된다. 의미적으로나 구현상으로나 업데이트가 끝날 때까지 부수효과 연산을 미뤄두는 것이 좋다.
예를 들어 DOM을 업데이트할 때는 requestAnimationFrame같은 스케쥴러에 맡기는게 더 좋을 수도 있다.
위에서 말한 이유로 do라는 메소드를 하나 만들텐데 부수효과 연산을 명시하는 것이다. fmap처럼
부수효과 함수를 받겠지만, 내부의 알림들(ready와 failed)이 완료될 때까지 지연될 것이다.
예를 들어
1
requestF('/url').do( val =>/* update ... */ )
이번에도 do의 의미와 리턴값이 무엇인지 생각해보자.
변이없이 그냥 Future를 리턴한다면 future.fmap( Id )(여기에서 Id는 x => x 같은 항등함수)
와 같은 형태이다. fmap과 다른 점은, 먼저 do에서 부수효과가 발생한다는 점이고 두번째는 다른
컨텍스트에서 실행된다는 점이다.(fmap은 즉시, do는 나중에). 가장 다른건 _의미_다.
정정: 2015년 4월 6일. Action이라는 새로운 타입을 통해 do를 적용했는데, 굳이 Monad(Future)
안에 다른 Monad(Action)을 넣어 복잡하게 만들 필요가 없었다. 서버에 데이터를 넘기거나 응답을
기다리는 등의 상황에서 리턴값이 필요할 수도 있는데, 다음 글에 이걸 개발해 볼 수도 있다.
덧붙여서, 비동기실행을 제대로 구현하려면 process.nextTick이나 MessageChannel 등을 사용해야
하지만 여기서는 간단히 구현하고 넘어가자. 비슷하게, 부수효과의 실패에 대응해 doError도 만들어야
하는데, do와 비슷하므로 각자 알아서 구현해보자. (Gist에 코드 전체가 있다)
역주 1: Promise와의 비교는 Future/Functor/Monad 개념을 이해하는데 관계없다고 생각해서 생략했다.
Translation of "Transitioning to Scala" into Korean, under the same license as the original.
2011년 말부터 2014년 초까지 전자상거래 솔루션 전문 에이전시, Nurun Toronto에서 리드개발자로 일했다. 자바와 스프링만으로 새로운 프로젝트들을 계속하다보니 대체제를 찾아야할 때라는걸 알게 되었다.
에이전시에서의 업무를 장기적인 관점에서 생각해봤다. "자바가 구리다"를 이해하지 못하는 고객들 때문에 마감에 시달렸다. 2004년도에 어플리케이션을 만들던 툴과 테크닉들은 2014년에는 별 도움이 되질 않았다. 2004년에는 코드 한줄을 테스트하기 위해 서버를 재시작하는게 당연했다 - 웹스피어는 재시작할 때 정체불명의 1200줄 XML 설정파일을 읽어오는데, 평균 걸리는 시간이 커피 한잔 마시고 오기 딱 좋은 120초 정도다. 요새는 이렇게 하면 에이전시나 개발자나 망한다.
우리가 만드는 어플리케이션들은 단순히 데이터베이스의 뷰어가 아니라, 매일매일 똥을 치워주는 소중한 도구다.
1. 왜 타입세이프의 스택을?
지난 프로젝트를 루비온레일즈로 진행해보고 뭘 싫은지를 알았다. 다른 동적 타입 언어도 인터프리트 언어도 상태기반 웹 프레임워크(stateful web framework)도 쓰기 싫었다. 자바 바이트코드로 컴파일되는 정적 타입 언어나 활발한 생태계를 가진 툴들, 그리고 확장성을 위한 무상태 웹 프레임워크가 더 괜찮았다. 또한 우리 고객사들은 믿을만한 회사를 통해 전문적인 기술지원을 받을 수 있어야 마음의 위안을 가졌다.
그래서 몇가지 선택지를 꼽아봤는데, 가장 먼저 타입세이프가 떠올랐다. 우리가 원하는 모든 것들이 있었다.
컨셉증명을 위해 초소형 전자상거래 사이트를 내부적으로 만들어서 스칼라의 단순함과 플레이의 개발 생산성에 대해서 시연했고 충분히 관심을 끌어서 결국 월마트 캐나다의 새로운 전자상거래 플랫폼의 토대가 되었다.
왜 스칼라가 복잡하다고 느낄까?
스칼라는 유연하다. 유연하다는 것은 단순하다는 것을 포기해야하는 일이지만, 다른 면으로 스칼라는 단순히 "자바보다 나은" 정도가 아니라 그보다 더 좋으며 매우 우아한 언어이다. 스칼라나 새로운 어떤 언어로의 전환이라는 큰 도전은 단지 기술적인 일만이 아니다. 능력있는 개발자라면 새로운 문법, 새로운 개념, 새로운 IDE를 배울 수 있다. 변화는 기술보다는 그 과정이나 문화같은 다른 면에서 어렵다.
짧게 말해서, 모든 것은 사람에 달려있다.
이 글의 뒷부분은 스칼라 프로그래밍 튜토리얼이 아니다. 이미 많은 글들이 있고, 고급 스칼라의 깊은 부분에 대한 최신 트릭을 가르칠 만큼 나는 인정받은 스칼라 개발자도 아니다. 이 뒤로는 스칼라로의 전환을 생각하고 있는 개발자들, 팀장 혹은 매니저들에게 전하는 조언들이다. 이 조언들은 기업용 스칼라 프로젝트를 이끌 때 개인적으로 한 경험을 토대로한 것들이다.
전업 스칼라 개발자로 경력 1년반이 지나고 엔터프라이즈 스칼라 프로젝트도 진행했지만, 마틴의 가이드에서 스칼라 개발자 등급 A2.5/L1.5라고 생각한다. A3/L3에 있는 테크닉들을 사용하지만, 웹 어플리케이션을 쭉 개발해오면서 대부분은 써본 적이 없다. 케이크 패턴을 써본 적도 없고, 고계도 타입(high-kinded type, 역주: 스칼라 학교에서는 상류 타입이라고 번역했는데, 하나의 Layer 위에 있다는 생각으로 고계高階를 생각해봤다)을 써본 적이 아직 없다. 그렇다고 나쁜 개발자도 아니고, 가면현상의 증상도 아니고, 단지 내 시간은 한정되어있고 가장 돈이 되는 것에 집중하려고 한다. 게다가 드럼도 치고 기타도 치고 일주일에 두번 댄스 레슨도 다니고 커피도 많이 마시고 데이트하러 나가야한다. 시간은 소중하니까.
Walmart.ca 프로젝트에서는 콤비네이터 파서와 폴드를 사용하지도 않고 레벨 가이드의 얇은 부분만을 썼다. "얇은" 스칼라로도 이전 플랫폼보다 훨씬 좋은 생산성을 보여줬다. 구현하는데 골치아픈 일도 없었다. 그렇게 짠 코드들은 이전보다 더 관리하기에도 좋고 생산성도 더 좋았다. 블랙 프라이데이나 박싱 데이(역주, 북미지역 등지에서 추수감사절 시즌/크리스마스 시즌에 대부분의 쇼핑몰들이 매년하는 대량할인 이벤트 기간들)에서의 확장도 완벽하게 돌아갔고, 많은 자바기반의 전자상거래 플랫폼은 하지 못했던 것들이다.
그래서 중요하지 않다는건가?
단순하게 스칼라를 쓴다는 것을 스칼라가 부족하다는 것으로 착각하지 마시길. A1과 A2 등급에서 익힐 수 있는 것들을 보자.
자바에 몇개 더 추가한 것과 비슷하다. 서술하듯이 개발하고 소프트웨어를 관리하는 새로운 방법이다. A3에 있는 몇개도 익히기 꽤 쉽고 - Akka나 다른 병렬 처리 라이브러리들을 사용하기 위해 꽤나 중요한 것들인데 - 그에 비해 크게 어렵지 않고 수학 학위가 필요할 정도는 아니다.
fold
stream, 혹은 지연평가 자료구조
actor
combinator parser
이런 테크닉들을 익혔을 때의 좋은 부가효과는, 사용하는 모든 언어에서 더 좋은 개발자가 된다는 것이다. 나는 스칼라와 자바스크립트 모두에서 클로저나 다른 테크닉들을 익히는데 정말 도움이 됐고 더 좋은 자바스크립트 프로그래머가 되었다.
2. 시간을 써라
자바에서 건너온 많은 스칼라 개발자들은 바로 적응하고 싶어하지만 스칼라는 완전히 다른 언어다. 새로운걸 익힌다는 것은 연습을 필요로 한다. 스칼라도 예외는 아니다.
좋은 소식은 A2/L1 등급만으로도 충분히 스칼라 어플리케이션을 만들만한 자격이 있다는 것이다. 모든 스칼라 개발자가 고급 순수함수 자료구조, 타입 이론, 고계도 타입을 이해하고 있을 필요는 없다. 하지만 스칼라는 차세대 어플리케이션을 만드는 전문 개발자를 위한 프로그래밍언어라는 것이다. 그래서 배우고 체득하는데 많은 시간이 걸릴 것이다.
이게 스칼라의 미학이다. 토니도 맞다. 틀린건 없고, 그냥 개인과 팀의 선택에 대한 문제다. 나는 <-:보다 reverse를 더 선호하지만, 내가 가독성과 단순성을 선호하는만큼 토니같은 개발자들은 수학적인 순수성과 사실성을 선호한다. 이 스타일들은 항상 다른 것 같다. 토니는 라이브러리들을 개발했고, 나는 라이브러리들로 어플리케이션을 만들고, 우리 둘 다 스칼라로 개발한다. 나는 가끔 var를 쓰고 나중에 걷어내지만, 누군가는 그걸 질색한다.
그런데 팀에서 사람들이 영어, 불어, 독어 같이 한 언어가 아닌 여러 언어를 쓴다고 해보자. 이럴 때 함수 이름을 영어 동사로 써도 그러려니 한다. 내가 같이 일했던 캐나다 사람들은 영어와 불어를 쓰는 사람들이 많았고, 헝크러진 머리나 좁쌀만한 눈(역주, 미국인이 캐나다인을 놀릴 때 주로 쓰는 표현)보다는 보기 괜찮다고 확신할 수 있다. 젠장(Sacré bleu!)
스칼라처럼 독선적이지 않은 언어는 그래서 아름답다. 자기 스타일을 자유롭게 적용할 수 있고, 언어가 그걸 방해하지 않는다. <-:도 쓸 수 있다는게 마음에 든다.
5. 주머니가 허락한다면 기술지원을 받아라
나는 운좋게도 타입세이프의 Nilanjan Raychaudhuri와 Roland Kuhn같은 진짜 고수들에게 배워서 Nurun에 설계 리뷰, 코드 리뷰, 페어 프로그래밍을 도입할 수 있었다. 새로운 프로그래밍 스타일을 배운 덕분에 신뢰도를 월등히 높인 프로젝트를 진행하면서 다방면으로 값으로 따질 수 없는 도움을 받았다.
단순히 스칼라의 함수형 스타일뿐만 배운게 아니라, 리액티브 프로그래밍 컨셉도 배웠다. Play와 Akka도. 새로운 테크닉들과 프로젝트 전반에 걸쳐 타입세이프의 도움을 많이 받았다. 우리가 항상 제대로 된 길을 가고 있는지에 대해 확신을 받았다.
타입세이프의 이메일 지원 역시 훌륭하다. 지원 구독은 주머니가 허락한다면 지출할 가치가 충분히 있다.
6. 다양성을 포용하라
스칼라 커뮤니티에는 전세계의 다양한 프로그래머들이 모여있다. 나처럼 전직 자바 개발자도 있고, 학계에서 온 사람들도 있다. 독학한 개발자도 있고 박사학위자들도 있다. 빠듯한 예산으로 사업문제를 해결하려 하는 사람들도 있고, 관심분야를 넓히려고 하는 사람들도 있다. 어플리케이션을 만드는 사람도 있고, 라이브러리를 만드는 사람도 있다.
커뮤니티의 모든 사람을 존중하고 이해하는게 좋은 개발자가 되는데 중요하다. StackOverflow에 단순한 질문을 올렸는데, 이해하려면 카테고리 이론을 몇년 배워야하는 난해한 답변이 달릴지도 모른다. 하지만 스칼라는 아직 새로운 언어이고 커뮤니티는 자기 색깔을 찾아가고 있다는 것을 염두에 둬라. 학계 출신이 아닌 개발자들이 스칼라 세계에 더 많아지고 더 많이 답변하다보면 토론은 조금 더 이론 개념보다는 어플리케이션 개념으로 옮겨갈 것이다.
답변에 실망했다면, 트위터의 Finagle이나 mDialog의 Smoke같은 라이브러리들의 소스코드를 봐라. 두 프로젝트는 제품 레벨에서도 많이 쓰이는 구현체로 훌륭한 스칼라 예제이다. 모든 스칼라가 어마어마하게 복잡하지는 않다.
7. 현실적인 목표를 설정하라
자바에서 온 신입 스칼라 개발자들은 하룻밤만에 고급 스칼라, 함수형 스칼라를 배울 수 없다는 사실을 깨달아야한다. 전형적인 비지니스 어플리케이션을 성공적으로 개발하는데 고급 함수형 스칼라가 필요한건 아니다.
함수형 프로그래밍을 접해본 개발자라면 스칼라 스타일로 익히데 시간이 덜 걸릴 것이다. 그렇지만 팀원들 대부분이 명령형 언어 개발자들이라면 스타일을 맞춰야할 것이다.
그리고 팀 밸런스에 대한 것인데, 유지보수해야할 사람이 이해할 수 있는 코드를 짜야할 것이다. 아무리 전세계에서 가장 우아한 코드라도 관리할 수 없으면 쓸모없다.
8. 짝코딩과 코드리뷰는 의무
짝코딩을 하면 팀 전체 스타일과 기술 평균에서 너무 멀어지지 않게 해주는데 효과적이다. 마지막으로 바라는게 필멸자들이 감히 범접할 수 없는 어려운 코드를 짜거나, 팀원들이 다들 준비가 될 때까지 다시 완벽하게 작동하는 명령형 코드로 짜는 것이다. 실험은 중요하지만, git은 두었다 무엇하는가. 포크해라, 두번해라.
팀원들이 이렇게 된다
스칼라의 유연성 덕분에 복잡함의 칼날을 피하는 것도, 언어의 새 기능이나 스칼라의 표현력을 익히기 쉽다. 문화는 언제나 개발팀에게 중요하지만, 더 중요한건 스칼라를 처음 배울 때 다같이 페달을 밟아 나가야한다는 것이다.
9. 간결함을 유지하라
스칼라는 새로운 것이고, 사람들은 무엇을 써야하고 무엇을 피해야할지 여전히 배우는 중이다. 더글라스 크록포드가 스칼라를 마스터하고 Scala: The Good Parts를 쓰기 전까지는, 언어의 각 부분에 대한 가치를 알아서 확인해야한다. 옳고 그름은 없고, 단지 시도와 실패만 있을 뿐이다. 뭐가 더 맞는지에 대해 얼마든 질문해라.
Reflection API가 처음 자바에 도입되었을 때, 모든 자바 개발자들이 자신들의 지적 능력을 동원해 모든 것에 리플렉션을 사용하려고 했다. 당시 내가 개발하던 코드들은 관리하기가 더럽게 복잡해졌고, 한 개발자가 미쳐날뛰어서 이해하지 못하는 기능을 남용했다는 것 말고 다른 이유는 없었다. 모든 생소한 기능은 발을 담그기 전에 천천히 깨끗하고 심플한 코드를 짜는게 더 낫다. 고급 테크닉을 이상하게 뒤죽박죽으로 구현한 것보다 깔끔하게 명령형 스타일로 스칼라 코딩을 하는게 차라리 낫다.
준비가 되기 전에 깊게 들어가지마라. 천천히 가자.
좋은 음악처럼 좋은 코드도 우아하고 드물다. 좋은 음식에 꼭 좋은 재료가 들어가는건 아니다. 상상할 수 있는 모든 향신료가 들어간 음식을 먹고 싶어할 사람이 있을까? 코드를 쓰는 것도 그렇다. A1급 개발자가 쓴 신뢰할만한 코드는 자기가 뭘 하고 있는지 왜 하는지도 모르며 제멋대로 짠 A3/L3급 개발자의 코드보다 더 관리하기 쉽다.
10. 구린 코드를 살펴봐라
심각하게 구린 스칼라 코드를 짤 수도 있고, 자바, 펄, 그리고 영어도 마찬가지다.
하지만 구린 자바코드와 구린 스칼라코드의 중요한 차이가 있다.
구린 스칼라 코드는 좀 다른 방식으로 구리다. 명령형으로 구리거나, 함수형으로 구리거나, 혹은 두가지가 섞인 채로 구리거나. 이해할 수 없을 정도로 구리다면 익숙하지 않은 스타일이라서 그럴 수도 있다. 스칼라는 새로운 언어라, 자바같은 성숙된 언어처럼 바로 안티패턴을 발견해내는게 아직은 어렵다. 그래서 개발팀들이 아름다운 코드를 구리다고 착각할 수도 있고, 구린 코드를 아름답다고 착각하게 될 수도 있다. 개발자들은 배운대로 구린 패턴을 짜기 시작하면 나중에는 더 구린 코드가 나온다. 그렇게 악순환이 된다.
나중에 고치려고 하는 것보다 처음부터 피하는게 더 좋다.
똑똑한 개발자가 스칼라로 이상하게 코딩한다면 불러봐라. 질문해라. 익히지 못한 언어에 대해 추측하지마라. 최악의 경우는, 잘못짰으면서 우아한 코드라고 생각은 하는데, 왜 우아한지 이해하지 못하는 경우다.
11. 스칼라는 단지 퍼즐의 일부분
웹 어플리케이션을 개발하는 방법은 10년전에 비하면 매우 다양하다. 요새는 스칼라, 플레이, AngularJS, MongoDB 앱을 개발한다. 내가 짜는 코드 대부분은 클라이언트단이다. 몇년간은 스칼라보다 Angular를 더 많이 짰는데, 나쁘다는게 아니라 그냥 현실이 그렇다.
스칼라의 미학은 자바처럼 쓸데없는 밑바닥을 만들어야하거나 루비같은 동적 언어의 불안함을 걱정할 필요없이 깔끔하고 안정적이고 성능좋은 서버단 코드를 짤 수 있게 해준다는 것이다. 스칼라로 짠 서버쪽 로직은 견고하기에 클라이언트쪽 코드를 안정적으로 짜는데 시간을 투자할 수 있다.
스칼라의 모든 쪽에서 마스터가 되고 싶어하는만큼 파고들어야할 기술들이 너무 많다. HTML5, SASS, AngularJS, RequireJS, SQL, MongoDB, 또, 또, 또.
한 언어의 모든 면을 마스터할 시간은 없겠지만, 스칼라는 맛을 보기만 해도 괜찮은 기술이다. Reactive Programming은 다음 세대의 대세가 될 것이며 그 패러다임 전환의 선두에 스칼라가 있을 것이라 믿는다. 성능과 안정성을 모두 얻을 수 있는 리엑티브 어플리케이션을 무시하기는 힘들다.
요즘엔 대부분 묵직한 XML 대신 JSON을 쓴다. SOA 패턴 대신 REST를 쓴다. 데스크탑 대신 모바일을 쓴다. 어마어마한 크기의 데이터에서 필요한 정보를 뽑아낼 때, Akka의 성능이라면 막대한 하드웨어를 투자하지 않고서도 가능하다.
스칼라는 퍼즐의 한 부분일 뿐이지만, 새로운 종류의 개발을 위해 필요한 다른 많은 부분들의 심장과도 같다.
12. 스칼라를 배우면 더 좋은 프로그래머가 된다
직장인 개발자가 자기 영역을 넓히는건 정말 드문 일이다. 소프트웨어 개발에서 완전히 다른 접근법을 배워본게 마지막으로 언제인가?
마지막 전환(그리고 내 경력에서 겪었던 유일한 전환)은 절차지향 언어에서 객체지향 언어로의 변환이었다. CIBC에서 인턴하던 1998년에 운좋게도 첫 자바 어플리케이션 개발자 중 하나가 될 수 있었다. 대부분의 개발자들은 전직 COBOL이나 C였다가 전환하는 시점이었다. 요새는 뭐든 다 자바를 쓰지만, 당시에 윈도우와 OS/2에 모두 배포해야하는 상황에서 자바는 매우 실용적이었다.
2-30년 경력의 개발자들(몇명은 실제로 펀치카드로 프로그래밍을 해봤던)과 일하면서 좋은 경험을 쌓았고, 한가지 스타일에 매이면 안된다는 것을 깨달았다. 자바를 배울 때 JCL도 관리해야했다. 바로 다시 복귀하기 몇달전까지는 old COBOL과 360 어셈블리도 파고들었다. 넓게 보자. JCL과 COBOL이 섹시한 언어는 아니지만 필요한 분야에서는 괜찮은 언어다. 인턴시절 스몰토크에서 엑셀까지 모든 것을 겪어볼 수 있었다. 엑셀은 처음 접한 함수형 프로그래밍이다. (역주: 엑셀이 함수형 프로그래밍을 지원하는지에 대한 StackExchange의 글이 댓글에 있다.)
스칼라는 부당한 평을 많이 받았다. 어떤 개발자들은 생각을 깊게 하기보다는 잠깐 시도해보고 익숙한 언어로 도망친다. 문제는 그 사람들이 인터넷에 남긴 불평들 때문에 관심있어하는 개발자들에게 언어의 가치가 잘못 전달될 수도 있다.
스칼라에 대한 불만을 읽는다면 누가 썼는지 찾아보기를. 다른걸 원한 사람일 수도 있다. 쉽게 흔들리지 말고, 불평하는 사람들에게 얽매이지 마라. 점점 널리 퍼져가는 스칼라의 성공사례들을 찾아보기를 바란다.
결론
스칼라는 기술뿐만이 아니라 문화적인 투자다. 투자할만한 가치가 있는 보상이 있는데, 어쨋든 해봐야하지 않을까? 확장가능하고 믿을만하고 관리하기 편한 프로젝트를 진행중이라면, 혹은 프로그래머로서 사고를 확장하고 싶다면 단언컨데 스칼라는 할만 하다. 기본만 있으면 보이는 것만큼 어렵지도 않다.
스칼라를 도전해본 것은 이번이 처음이 아니다. 함수형에 대해 이름만 알던 차에 자바 개발자를 위한 함수형 프로그래밍를 읽고 함수형이라는 개념을 더 배우고 싶어했고, 코세라(Coursera)에 가입하게 된 계기이자 처음으로(그리고 현재로서는 마지막으로) 수료한 스칼라로 배우는 함수형 프로그래밍 기초로 함수형이라는 패러다임을 잠깐 맛보았다. 그리고 1년 정도 손을 놓았다가 리액티브 프로그래밍 기초에 다시 도전했다가 영어 실력의 한계와 스칼라의 이해가 부족했다라는 점만 뼈저리게 깨닫고 중도포기를 했다. 그리고 쉽게 배워서 빨리 써먹는 스칼라 프로그래밍를 통해 문법은 리뷰할 수 있었지만 언어 자체와 함수형에 대한 이해도가 좋아지진 않았다.
스칼라를 더 공부해보고 싶다는 막연한 생각은 가지고 있었고, 함수형에 대한 재미 때문에 underscore/lo-dash를 다양하게 써본다거나 함수형 자바스크립트 책을 재미있게 읽기도 했고, 파이썬을 다시 써볼까 싶어서 나간 스터디에서 프로젝트 오일러의 문제를 최대한 함수형으로 풀어보면서 더 간결한 코드 작성이 가능해졌다는걸 느꼈다. 그러던 차에 내가 들었던 두 강의의 교수이자 스칼라를 만든 마틴 오더스키의 책, 스칼라 프로그래밍 2판 번역판이 출간된다는 이야기에 많이 기대하고 있었다. 책 내용과 관련없는 이야기를 길게 늘어놓은 이유는, 내가 생각하기에 나는 초심자와 다름없는 수준같지만 그래도 완전히 스칼라를 처음 접하는 사람과 느끼는 부분이 다를 수 있어서 겪어온 과정을 적어봤다.
첫번째 장에서는 스칼라의 특징들에 대한 설명과 어떤 언어에서 어떤 장점들을 가져온 것인지에 대해 나열하며 앞으로 배울 것들에 대해 개요를 보여준다. 하지만 언어론에 대해 관심이 있는 사람이 아니라면 적당히 훑어보고 나중에 다시 읽거나 아니면 구조적인 내용(10장 상속과 구성)이 나오기 전까지 읽고 나서 언어에 대한 감을 잡고 다시 1장을 읽어보기를 권한다. 1장을 (체감상)세 호흡 정도로 읽었다면 2장부터 9장까지는 거의 한 호흡에 집중해서 쭉 읽었다.
2장부터는 필요할 때 REPL로 한줄 정도 테스트해보면서 쭉 읽어나갔다. 그래도 문법에 대해서는 어느 정도 알고 있어서 무난히 넘어가긴 했지만, 이 책으로 처음 스칼라를 접한 사람들에게는 코딩을 시도해볼 여지가 별로 없다. 새로운 언어를 배울 때 이것저것 시도해보면서 체득하는 것이 중요하다고 생각해서 이 책의 그나마 단점이 있다면 그런 면이 아닐까 생각한다. 위에서 언급한 쉽게 배워서~의 경우에는 설명이 빈약해서 그 책만으로 스칼라를 이해하기 어렵지만 챕터마다 연습문제가 있어서 이 책을 읽으면서 같이 진행한다면 좋은 부교재가 되지 않을까 싶다.
추천 챕터
오랜만에 끝까지 정독한 책이지만 아직 완전히 이해했다고 생각하지 않아서 챕터들에 대해 평가를 내리기 조심스럽지만, 그래도 이 책을 읽을 사람들을 위해서 꼭 두번 읽고 넘어가라고 권해주고 싶은 챕터들이 있어서 메모를 해뒀다.
12.7 트레이트냐 아니냐, 이것이 문제로다: 어떨 때 트레이트로 만들어야하는지에 대한 가이드라인
15.1 패턴 매치(p322-324): 패턴매치가 어떻게 작동하는지에 대해 화이트박스로 설명하는 자세한 가이드
16.10 스칼라의 타입 추론 알고리즘 이해: 어떤 순서와 힌트로 타입을 추론하는지에 대한 매카니즘과 현재 불가능한 점.
22.1 List 클래스 개괄: 함수형 언어들에서 List(정확히는 cons 구조)가 왜 중요한지, 그리고 이 구조를 이해해야 지연 평가를 이해
24.15 뷰: Scala를 Scala답게 쓰기 위한 기능(자세히 설명하기 어렵지만 읽고 나면 이해될 것이다)
외부 라이브러리 사용
그리고 책에서는 scala.actors.Actor가 2.11부터 삭제예정(deprecated)이니 akka를 사용할 것을 권장하고 있는데, 2.11.0부터 아예 패키지 자체가 삭제되었다. 또, 2.11.0부터 독립한 다른 라이브러리들도 있다. Scala 2.11.0 API 페이지를 보면 다음과 같은 부분이 있다.
scala.reflect - Scala's reflection API (scala-reflect.jar)
scala.xml - XML parsing, manipulation, and serialization (scala-xml.jar)
scala.swing - A convenient wrapper around Java's GUI framework called Swing (scala-swing.jar)
scala.util.continuations - Delimited continuations using continuation-passing-style (scala-continuations-library.jar, scala-continuations-plugin.jar)
scala.util.parsing - Parser combinators, including an example implementation of a JSON parser (scala-parser-combinators.jar)
scala.actors - Actor-based concurrency (deprecated and replaced by Akka actors, scala-actors.jar)
책을 기준으로 akka를 제외하고 28장 XML 다루기(scala-xml.jar), 33장 콤비네이터 파싱(scala-parser-combinators.jar), 34장 GUI 프로그래밍(scala-swing.jar)이 해당된다. 신기한 것은 REPL로 한줄씩 테스트해볼 때는 몰랐는데, scala-xml이 독립했다는걸 보고 이클립스에서 프로젝트로 만들어서 실험해봤더니 XML 표현법(literal)에서 에러가 났다. REPL(scala)의 경우, bash script 파일인데 여기서 기본 라이브러리(homebrew로 설치한 경우 /usr/local/Cellar/scala/2.11.4/libexec/lib)를 classpath로 추가해서 실행되므로 가능한 것이다.
외부 라이브러리를 어떻게 사용하는지에 대해 나와있지 않아서 sbt를 사용해보려고 검색하다가 이 책의 역자인 오현석님께서 번역하신 트위터의 스칼라 학교의 빌드 도구 SBT(Simple Build Tool) 챕터를 참고해 시도해보려고 했지만, 간단한 의존성 추가에 너무 많은 공수가 들어서 sbt 레퍼런스에서 라이브러리 의존성를 참고해 build.sbt을 작성했다. 예를 들어 akka-actor만 추가할 경우에
이런 식으로 프로젝트 루트에 build.sbt파일을 만들고, sbt update를 통해 가져온 뒤 sbt eclipse를 통해 이클립스에 import할 수 있는 프로젝트를 생성할 수 있다.
akka
책의 예제는 scala.actors가 기준이라 akka.actor로 예제 소스를 다시 쓰고 싶었지만 제대로 이해하지 못해서 도움이 될만한 글을 검색하던 도중 오현석님의 프로그래밍 인 스칼라 액터 예제 akka로 변환하기(1) - 간단한 액터를 발견해서 이 글과 마이그레이션 가이드를 읽고 시도해보려다가 잘 안돼서 다시 검색하던 도중 누군가 만들어준 프로젝트를 발견했다. 혹시 필요한 분들을 위해 남겨둔다.
책을 읽으면서 간략하게 메모해놓은 것을 토대로 짧은 후기와 함께 같은 고생을 할 분들을 위해 약간의 도움을 남기고자했는데 의외로 글이 길어졌다. 스칼라를 배우면서 좋았던건 처음에 언급했던 것처럼 함수형이라는 패러다임에 대한 이해에 도움이 된다는 것이었다. 설계부터 변경할 수 없는 값(immutable)이나 지연평가 등 함수형을 잘 살릴 수 있는 구조로 만들수도 있지만, 평소에 하던 스타일에 크게 변형을 주지 않으면서도 세세한 부분의 조금 더 좋게 개선할 수 있는 직교적(orthogonal)인 개념이라는 점에서 누구에게나 도움이 될 수 있지 않을까 생각한다. 다른 패러다임들이 무엇이 있을지 궁금해하던 차에 이 책을 읽는 도중에 발견했던 글이 있는데, AI의 대부격이라는 피터 노빅의 "프로그래밍 10년 완성"이라는 글에서 눈에 들어온 문단을 인용해본다.
프로그래밍을 정복하기 위한 나만의 비법이 있다:
최소 다섯가지 프로그래밍 언어를 배워라. class abstractions (자바 또는 C++) 지원하는 언어, coroutines을 (Icon 또는 Scheme) 지원하는 언어, functional abstraction (Lisp 또는 ML) 지원하는 언어, syntactic abstraction (Lisp) 지원하는 언어, declarative specifications를 (Prolog또는 C++ 템플렛) 지원하는 언어, 그리고 parallelism을 (Sisal) 지원하는 언어를 한개씩 배워라.
우리는 Potluck에서 iOS앱에서 인터렉션을 테스트해보고 프로토타이핑을 하기 위해 Framer.js를 사용하기 시작했다. Framer는 모바일과 데스크탑 앱에서의 인터렉션 프로토타이핑과 에니메이션을 위한 자바스크립트 프레임워크다. 쿼츠 콤포저(Quartz Composer)보다 러닝커브가 훨씬 낮고 아이폰과 데스크탑 양쪽에서 쉽게 실행할 수 있는 훌륭한 대안이다. 키노트에서 시작해서 실제같은 인터렉티브 프로토타입을 단계별로 만들 수 있다.
자바스크립트 기반이기 때문에 특히 드래그나 스와이프같은 복잡한 제스쳐를 만들 때 좋다. 스와이프 거리에 따라 엘리먼트를 움직이거나 사라지게할 때 혹은 특정거리 이상 스와이프할 때 액션이 발생하도록 할 수 있다.
신생 프로젝트라 예제나 문서들이 너무 없다. 그래서 배웠던 것들을 공유하려고 생각했다.
시작하기 전에 타이핑하기 귀찮은 사람을 위해 [CodePen](http://codepen.io/seoh/full/AqycD에 완성본을 올려놨다.
Activate on release
다른 액션을 가진 테이블 셀들로 간단한 예제를 시작해보자.
일단 보통 아이폰 스크린을 표시하기 위한 컨테이너 뷰를 만들어보자. 시스템 상태바를 가진 웹앱을 프로토타이핑하기 위해 높이는 598px로 정했다. (역주, 원문에서는 1096px였지만 웹에서 확인하기 좋게 절반으로 줄였다.)
셀에서 사용자에게 보이는 부분을 정한 컨테이너를 만들고, 화면 밖에서 슬라이드하면 셀이 나타나도록 할 것이다.
이렇게 보일 것이다.
이제 셀에 드래그를 추가해보자.
원하는 기능은 아니지만 어디로든 드래그할 수 있다.
더 구체적인 제스쳐를 구현하기 위해 드래그 이벤트 핸들러를 사용할 수도 있다. 뭔가 드래그할 때 세가지 이벤트가 발생한다. Events.DragStart는 드래그를 시작할 때 한번, Events.DragEnd는 드래그를 놓았을 때 한번 발생한다. Events.DragMove는 마우스나 손가락을 움직일 때 계속 발생한다.
draggable은 "speed" 속성을 갖는데 마우스 움직임에 따라 어느 정도의 속도로 움직일지 결정한다. 속도를 0으로 설정하면 물체가 해당하는 방향(축)으로 이동하지 않게 된다.
드래그가 끝났을 때 무엇을 할지 정할 수도 있는데, 여기에서는 원래 물체를 자리로 돌아가게 해보자.
이제 화면 밖의 엘리먼트가 드래그할 때 나타나도록 해보자. 그 엘리먼트는 셀 컨테이너의 차일드 뷰가 될 것이고(그래서 셀과 함께 움직일 것이고) 그냥 화면 밖에 놓도록 하겠다.
이 액션 바를 추가한 다음에 셀을 왼쪽으로 끌면 화면 오른쪽 끝에서 나타나는걸 볼 수 있다.
좀 재미있는걸 넣어보자. 드래그 핸들러는 액션 바를 조금이라도 움직일 때마다 실행되는데, 얼마나 셀을 움직이는지에 따라 색깔을 바꾸게 만들 수 있다.
(얼마나 셀을 움직였는지에 대한)범위를 다른 (바의 색상)범위로 바꾸는 것은 Utils.mapRange 함수를 통해 쉽게 할 수 있다.
(역주: 원문은 원래 framerjs 2를 기준으로 작성되어 Proccessing 프레임워크의 map_range라는 함수를 사용했는데 중요한 정보는 아니다.)
이 함수에서는 [low1, high1] 범위에 있는 value를 [low2, high2] 범위에서의 같은 위치(비율)로 변환해준다. 이제 셀의 x축 좌표를 액션 바의 투명도로 바꿔보자.
셀을 드래그할 때 액션 바의 색은 다음과 같이 변한다.
충분히 액션 바를 드래그했을 때는 그대로 열려있도록 만들고 싶다. 이걸 하려면, DragEnd 핸들러에서 얼마나 드래그되었는지 확인하고 특정 너비를 넘었다면 계속 열려있도록 해보자.
Activate on threshold
탭을 밀었을 때 계속 열려있도록 해봤다. 탭까지 가지 않고 액션을 할 수는 없을까? iOS 6의 당겨서 새로고침이 좋은 예다. 충분히 당기면 탭까지 가지 않아도 새로고침이 일어난다. (역주, 여기에서는 특정 길이만큼 드래그 후 이벤트 발생으로 애니메이션을 실행하는 것까지만 예제로 한다.)
위아래로 움직이는 두번째 셀을 만들어보자.
셀을 100px 아래로 내리면 쪼그라들게 해보자. 일단 이렇게 시도해봤다.
애니메이션이 좀 산만하다. 드래그할 때마다 계속 DragMove 이벤트가 발생하고 계속 애니메이션을 시작하려고 한다. 그래서 조건이 만족될 때 딱 한번만 발생하도록 해보자.
(역주, 원문에서는 Drag와 Animate 기능이 충돌해서 제대로 Animate가 작동하지 않아 Drag하는 레이어와 Animate되는 레이어를 따로 뒀는데 버그가 수정되었는지 잘 작동해서 그 이하 부분은 생략했다.)
아이폰에서 테스트
Framer Studio 1.7에서 Mirror라는 굉장히 편한 기능이 추가되었다. Studio에서 작업한 내용을 저장하고 Mirror 버튼을 누르면 작업중인 컴퓨터를 자동으로 서버로 사용해서 외부에서 접근할 수 있는 주소를 생성해준다. (역주, 원문에서는 Dropbox Public folder에 대한 내용이었지만 Mirror 기능이 더 유용하다고 생각해서 변경했다.)
클로저는 사용자의 코드 안에서 전달되거나 사용할 수 있는 기능을 포함한 독립적인 블록(block)입니다. Swift에서의 클로저는 C 및 Objective-C 의 blocks와 유사하며, 다른 언어의 람다(lambda)와도 유사합니다. 클로저는 자신이 정의된 컨텍스트(context)로부터 임의의 상수 및 변수의 참조(reference)를 획득(capture)하고 저장할 수 있습니다.
3번의 경우를 더 간단하게 만들기 위해서 JavaScript의 즉시실행함수(IIFE)를 흉내내고 싶었는데, Swift의 버그 때문에 현재 단순히 값만 리턴하는 IIFE도 var는 안되고 let을 써야 타입 추론이 가능하며, let을 쓰더라도 함수를 리턴하는 경우에도 에러가 나고, IIFE 속에서 조건문(conditional statement)이 존재할 경우 경우의 수에 대한 superset을 추론하는게 아니라 그냥 에러가 난다.
2. 부분함수와 합성함수의 단계적 구현
2.1. 기본 구현
Swift에서도 함수형 프로그래밍 스타일을 지원하도록 Array에 filter, map, reduce 등의 메소드들이 존재해서 array.filter{}.map{}.reduce(){} 같은 스타일로 작성할 수 있다. 그래서 특정 조건까지의 배열을 뽑아서(take) filter와 map을 체이닝해서 변이(tramsform)된 배열을 구하는 문제부터 시작했다. 앞/뒤에서 특정 길이만큼 읽는 함수는 Swift의 기본 라이브러리에서 prefix와suffix를 통해 지원하고 함수형 프로그래밍에서는 보통 take/takeRight라는 이름으로 지원된다. 특정 조건까지 읽는 함수는 takeWhile이라고 보통 부르는데, Swift에서 구현되어있지 않아서 도장에서는 ExSwift에 있는 takeWhile의 소스가 제공되었다.
2.2. Pythonic solution
Python, underscore.js처럼 filter/map/reduce라는 함수에 sequence를 인자로 넘기는 식으로 개발을 하다보면 체이닝이 아니라 reduce(map(filter(... 처럼 전역함수를 이용해 구현할 수도 있는데, 이럴 경우에는 실행되는 순서와 함수호출의 순서가 역순이고, 값을 평가하는 함수를 인자로 넘길 때 인자로 받는 전역함수와의 거리가 멀어져서 가독성이 떨어지는 문제가 생긴다. 이 문제를 부분 함수(partial function)와 합성 함수(compose function)을 이용해서 인자를 받는 순서를 바꾸면 훨씬 가독성이 올라간다.
2.3. Functional Programming
함수형 프로그래밍으로 구현하기 위해서는 일단 1급 시민(first-class citizen, 혹은 1급 함수나 1급 객체 등으로 불린다)이라는 개념에 대해 이해가 먼저 필요하다. Java의 경험이 있다면 함수형 언어로 가는 길 (중편) - 일급객체, JavaScript의 경험이 있다면 Javascript : 함수(function) 다시 보기라는 자세한 설명의 글들이 있고 영문으로는 더 자세하고 풍부한 자료들이 있다. 그리고 함수형 프로그래밍에 대한 패러다임의 이해도 필요한데, 가장 좋은 방법은 함수형 프로그래밍을 지원하는 언어를 배우는 것이다. Twitter에서 만든 Scala School이라는 Scala 입문 강의가 있는데 한글 번역도 존재한다. 혹은 Java 경험이 있다면 자바 개발자를 위한 함수형 프로그래밍라는 eBook을, JavaScript 경험이 있다면 함수형 자바스크립트라는 좋은 책들도 있다.
2.4. Solution
다시 도장 이야기로 돌아가서, 이 문제를 해결하기 위해 영후님은 F#이라는 언어의 pipe-forwarding(|>)이라는 연산자를 구현하셨다. Swift에서의 pipe-forwarding |>의 구현이라는 글을 읽어보면 구현체와 그 설명이 자세히 나와있다.
도장에서 나온 문제와 일치하지는 않지만 위에 나온 과정들을 종합해보면 이런 예제를 만들 수 있다.
let list = [1,2,3,4,5] |> ifilter { $0%2==0 } |> imap { $0*2 } |> imap { String($0) }
println(list) // ["4", "8"]
3. Accumulator
누산기(accumulator)는 함수 하나를 리턴하는데, 그 함수는 인자를 하나 받을 때마다 그 값들이 누산된 결과를 리턴한다. 클로저에서 값을 캡처해서 리턴하는 것은 1번 문제에서 했고, 캡처된 값을 변경하도록 하는 것과 파라미터로 정의된 값을 다시 변수로 사용해서 소스코드를 짧게 만들도록 구현하는게 목적이었다.
4. Jensen's Device
이번에도 알고리즘 문제가 하나 나왔다. Jensen's Device라는 문제로 한 변수를 캡처하고 있는 클로저를 계속 이용해서 따로 변수 선언없이 파라미터만으로 문제를 해결하도록하는 문제였다. 인자로 넘길 때 스코프 명시({})없이 쓸 수 있도록 해주는 @auto_closure라는 키워드에 대해 배웠다.
5. Conclusion
1회의 난이도가 1이었다면 이번 난이도는 10쯤 된다. 다음의 난이도는 얼마나 될지 모르겠다.